Disaster Recovery
When using the PostgreSQL Operator, the answer to the question “do you take backups of your database” is automatically “yes!”
The PostgreSQL Operator leverages a pgBackRest repository to facilitate the usage of the pgBackRest features in a PostgreSQL cluster. When a new PostgreSQL cluster is created, it simultaneously creates a pgBackRest repository as described in creating a PostgreSQL cluster section.
For more information on how disaster recovery in the PostgreSQL Operator works, please see the disaster recovery architecture section.
Creating a Backup
The PostgreSQL Operator uses the open source pgBackRest backup and recovery utility for managing backups and PostgreSQL archives. pgBackRest has several types of backups that you can take:
- Full: Back up the entire database
- Differential: Create a backup of everything since the last full back up was taken
- Incremental: Back up everything since the last backup was taken, whether it was full, differential, or incremental
When a new PostgreSQL cluster is provisioned by the PostgreSQL Operator, a full pgBackRest backup is taken by default.
To create a backup, you can run the following command:
pgo backup hippo
which by default, will create an incremental pgBackRest backup. The reason for this is that the PostgreSQL Operator initially creates a pgBackRest full backup when the cluster is initial provisioned, and pgBackRest will take incremental backups for each subsequent backup until a different backup type is specified.
Most pgBackRest options are supported and can be passed in by the PostgreSQL Operator via the --backup-opts flag.
Creating a Full Backup
You can create a full backup using the following command:
pgo backup hippo --backup-opts="--type=full"
Creating a Differential Backup
You can create a differential backup using the following command:
pgo backup hippo --backup-opts="--type=diff"
Creating an Incremental Backup
You can create a differential backup using the following command:
pgo backup hippo --backup-opts="--type=incr"
An incremental backup is created without specifying any options after a full or differential backup is taken.
Creating Backups in S3
The PostgreSQL Operator supports creating backups in S3 or any object storage system that uses the S3 protocol. For more information, please read the section on PostgreSQL Operator Backups with S3 in the architecture section.
Set Backup Retention
By default, pgBackRest will allow you to keep on creating backups until you run out of disk space. As such, it may be helpful to manage how many backups are retained.
pgBackRest comes with several flags for managing how backups can be retained:
--repo1-retention-full: how many full backups to retain--repo1-retention-diff: how many differential backups to retain--repo1-retention-archive: how many sets of WAL archives to retain alongside the full and differential backups that are retained
For example, to create a full backup and retain the previous 7 full backups, you would execute the following command:
pgo backup hippo --backup-opts="--type=full --repo1-retention-full=7"
pgBackRest also supports time-based retention. Please review the pgBackRest documentation for more information.
Schedule Backups
It is good practice to take backups regularly. The PostgreSQL Operator allows you to schedule backups to occur automatically.
The PostgreSQL Operator comes with a scheduler is essentially a cron server that will run jobs that it is specified. Schedule commands use the cron syntax to set up scheduled tasks.
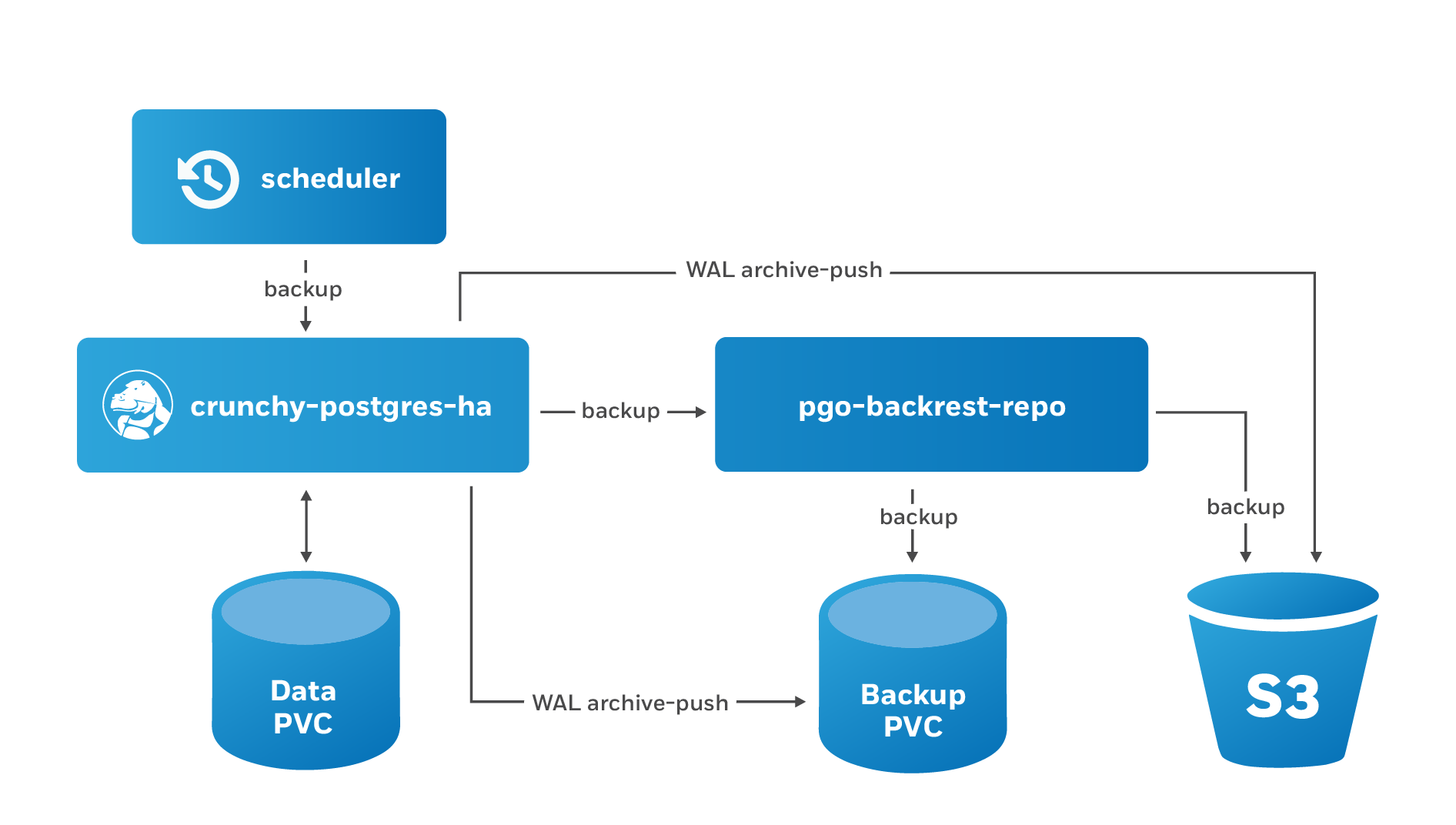
For example, to schedule a full backup once a day at 1am, the following command can be used:
pgo create schedule hippo --schedule="0 1 * * *" \
--schedule-type=pgbackrest --pgbackrest-backup-type=full
To schedule an incremental backup once every 3 hours:
pgo create schedule hippo --schedule="0 */3 * * *" \
--schedule-type=pgbackrest --pgbackrest-backup-type=incr
You can also add the backup retention settings to these commands.
View Backups
You can view all of the available backups in your pgBackRest repository with the pgo show backup command:
pgo show backup hippo
Restores
The PostgreSQL Operator supports the ability to perform a full restore on a PostgreSQL cluster (i.e. a “clone” or “copy”) as well as a point-in-time-recovery. There are two types of ways to restore a cluster:
- Restore to a new cluster using the
--restore-fromflag in thepgo create clustercommand. This is effectively a clone or a copy. - Restore in-place using the
pgo restorecommand. Note that this is destructive.
It is typically better to perform a restore to a new cluster, particularly when performing a point-in-time-recovery, as it can allow you to more effectively manage your downtime and avoid making undesired changes to your production data.
Additionally, the “restore to a new cluster” technique works so long as you have a pgBackRest repository available: the pgBackRest repository does not need to be attached to an active cluster! For example, if a cluster named hippo was deleted as such:
pgo delete cluster hippo --keep-backups
you can create a new cluster from the backups like so:
pgo create cluster datalake --restore-from=hippo
Below provides guidance on how to perform a restore to a new PostgreSQL cluster both as a full copy and to a specific point in time. Additionally, it also shows how to restore in place to a specific point in time.
Restore to a New Cluster (aka “copy” or “clone”)
Restoring to a new PostgreSQL cluster allows one to take a backup and create a new PostgreSQL cluster that can run alongside an existing PostgreSQL cluster. There are several scenarios where using this technique is helpful:
- Creating a copy of a PostgreSQL cluster that can be used for other purposes. Another way of putting this is “creating a clone.”
- Restore to a point-in-time and inspect the state of the data without affecting the current cluster
and more.
Restore Everything
To create a new PostgreSQL cluster from a backup and restore it fully, you can execute the following command:
pgo create cluster datalake --restore-from=hippo
Partial Restore / Point-in-time-Recovery (PITR)
To create a new PostgreSQL cluster and restore it to specific point-in-time (e.g. before a key table was dropped), you can use the following command, substituting the time that you wish to restore to:
pgo create cluster datalake \
--restore-from hippo \
--restore-opts "--type=time --target='2019-12-31 11:59:59.999999+00'"
When the restore is complete, the cluster is immediately available for reads and writes. To inspect the data before allowing connections, add pgBackRest’s --target-action=pause option to the --restore-opts parameter.
The PostgreSQL Operator supports the full set of pgBackRest restore options, which can be passed into the --backup-opts parameter. For more information, please review the pgBackRest restore options
Restore in-place
Restoring a PostgreSQL cluster in-place is a destructive action that will perform a recovery on your existing data directory. This is accomplished using the pgo restore
command. The most common scenario is to restore the database to a specific point in time.
Point-in-time-Recovery (PITR)
The more likely scenario when performing a PostgreSQL cluster restore is to recover to a particular point-in-time (e.g. before a key table was dropped). For example, to restore a cluster to December 31, 2019 at 11:59pm:
pgo restore hippo --pitr-target="2019-12-31 11:59:59.999999+00" \
--backup-opts="--type=time"
When the restore is complete, the cluster is immediately available for reads and writes. To inspect the data before allowing connections, add pgBackRest’s --target-action=pause option to the --backup-opts parameter.
The PostgreSQL Operator supports the full set of pgBackRest restore options, which can be passed into the --backup-opts parameter. For more information, please review the pgBackRest restore options
Next Steps
There are cases where you may want to take logical backups, aka pg_dump / pg_dumpall. Let’s learn how to do that with the PostgreSQL Operator!