Using Custom Resources
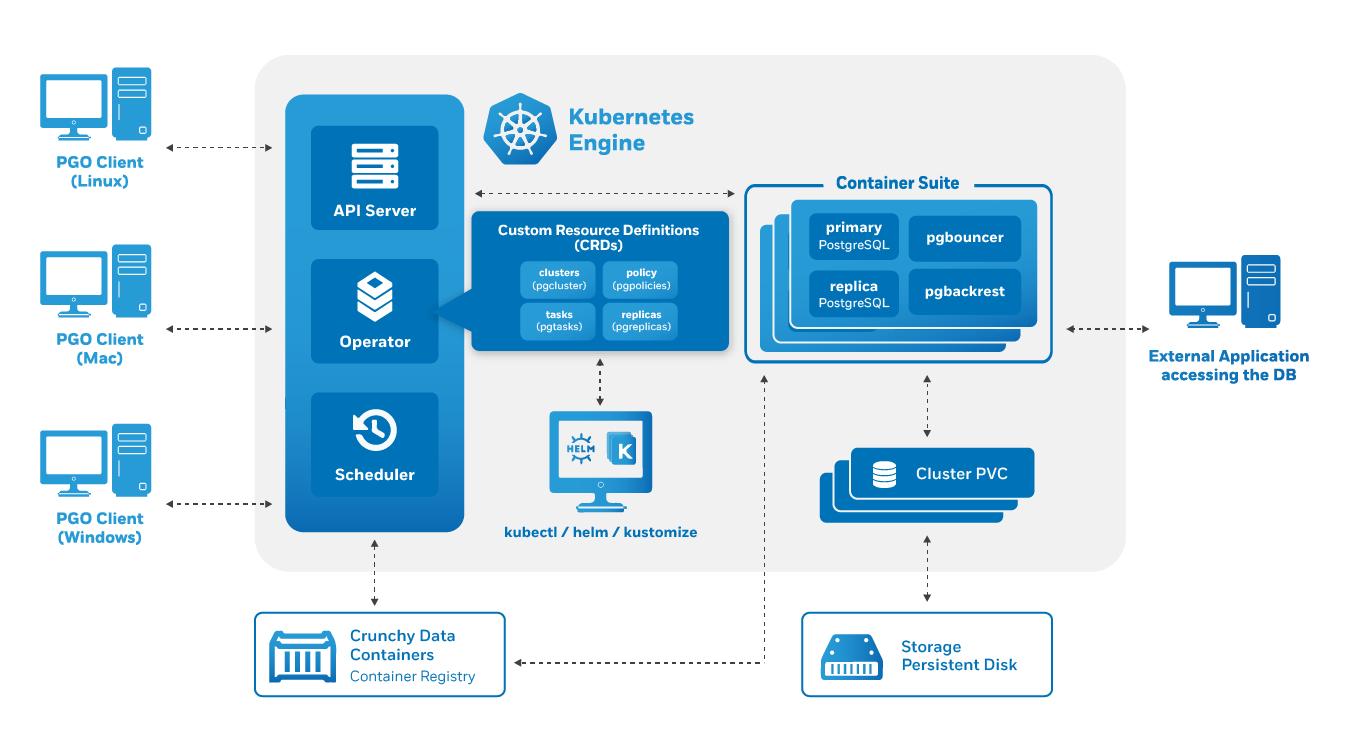
As discussed in the architecture overview, the heart of the PostgreSQL Operator, and any Kubernetes Operator, is one or more Custom Resources Definitions, also known as “CRDs”. CRDs provide extensions to the Kubernetes API, and, in the case of the PostgreSQL Operator, allow you to perform actions such as:
- Creating a PostgreSQL Cluster
- Updating PostgreSQL Cluster resource allocations
- Add additional utilities to a PostgreSQL cluster, e.g. pgBouncer for connection pooling and more.
The PostgreSQL Operator provides the pgo client
as a convenience for interfacing with the CRDs, as manipulating the CRDs
directly can be a tedious process. For example, there are several Kubernetes
objects that need to be set up prior to creating a pgcluster custom resource
in order to successfully deploy a new PostgreSQL cluster.
The Kubernetes community trend has been to move towards supporting a
“custom resource only” workflow for using Operators, and this is something that
the PostgreSQL Operator aims to do as well. Certain workflows are fully driven
by Custom Resources (e.g. creating a PostgreSQL cluster), while others still
need to interface through the pgo client
(e.g. adding a PostgreSQL user).
The following sections will describe the functionality that is available today when manipulating the PostgreSQL Operator Custom Resources directly.
Custom Resource Workflows
Create a PostgreSQL Cluster
The fundamental workflow for interfacing with a PostgreSQL Operator Custom Resource Definition is for creating a PostgreSQL cluster. There are several that a PostgreSQL cluster requires to be deployed, including:
- Secrets
- Information for setting up a pgBackRest repository
- PostgreSQL superuser bootstrap credentials
- PostgreSQL replication user bootstrap credentials
- PostgresQL standard user bootstrap credentials
Additionally, if you want to add some of the other sidecars, you may need to create additional secrets.
The good news is that if you do not provide these objects, the PostgreSQL Operator will create them for you to get your Postgres cluster up and running!
The following goes through how to create a PostgreSQL cluster called
hippo by creating a new custom resource.
# this variable is the name of the cluster being created
export pgo_cluster_name=hippo
# this variable is the namespace the cluster is being deployed into
export cluster_namespace=pgo
cat <<-EOF > "${pgo_cluster_name}-pgcluster.yaml"
apiVersion: crunchydata.com/v1
kind: Pgcluster
metadata:
annotations:
current-primary: ${pgo_cluster_name}
labels:
crunchy-pgha-scope: ${pgo_cluster_name}
deployment-name: ${pgo_cluster_name}
name: ${pgo_cluster_name}
pg-cluster: ${pgo_cluster_name}
pgo-version: 4.7.16
pgouser: admin
name: ${pgo_cluster_name}
namespace: ${cluster_namespace}
spec:
BackrestStorage:
accessmode: ReadWriteMany
matchLabels: ""
name: ""
size: 1G
storageclass: ""
storagetype: dynamic
supplementalgroups: ""
PrimaryStorage:
accessmode: ReadWriteMany
matchLabels: ""
name: ${pgo_cluster_name}
size: 1G
storageclass: ""
storagetype: dynamic
supplementalgroups: ""
ReplicaStorage:
accessmode: ReadWriteMany
matchLabels: ""
name: ""
size: 1G
storageclass: ""
storagetype: dynamic
supplementalgroups: ""
annotations: {}
ccpimage: crunchy-postgres-ha
ccpimageprefix: registry.developers.crunchydata.com/crunchydata
ccpimagetag: ubi8-13.16-4.7.16
clustername: ${pgo_cluster_name}
database: ${pgo_cluster_name}
exporterport: "9187"
limits: {}
name: ${pgo_cluster_name}
pgDataSource:
restoreFrom: ""
restoreOpts: ""
pgbadgerport: "10000"
pgoimageprefix: registry.developers.crunchydata.com/crunchydata
podAntiAffinity:
default: preferred
pgBackRest: preferred
pgBouncer: preferred
port: "5432"
tolerations: []
user: hippo
userlabels:
pgo-version: 4.7.16
EOF
kubectl apply -f "${pgo_cluster_name}-pgcluster.yaml"
And that’s all! The PostgreSQL Operator will go ahead and create the cluster.
As part of this process, the PostgreSQL Operator creates several Secrets that contain the credentials for three user accounts that must be present in order to bootstrap a PostgreSQL cluster. These are:
- A PostgreSQL superuser
- A replication user
- A standard PostgreSQL user
The Secrets represent the following PostgreSQL users and can be identified using the below patterns:
| PostgreSQL User | Type | Secret Pattern | Notes |
|---|---|---|---|
postgres |
Superuser | <clusterName>-postgres-secret |
This is the PostgreSQL superuser account. Using the above example, the name of the secret would be hippo-postgres-secret. |
primaryuser |
Replication | <clusterName>-primaryuser-secret |
This is for the managed replication user account for maintaining high availability. This account does not need to be accessed. Using the above example, the name of the secret would be hippo-primaryuser-secret. |
| User | User | <clusterName>-<User>-secret |
This is an unprivileged user that should be used for most operations. This secret is set by the user attribute in the custom resources. In the above example, the name of this user is hippo, which would make the Secret hippo-hippo-secret |
To extract the user credentials so you can log into the database, you can use the following JSONPath expression:
# namespace that the cluster is running in
export cluster_namespace=pgo
# name of the cluster
export pgo_cluster_name=hippo
# name of the user whose password we want to get
export pgo_cluster_username=hippo
kubectl -n "${cluster_namespace}" get secrets \
"${pgo_cluster_name}-${pgo_cluster_username}-secret" -o "jsonpath={.data['password']}" | base64 -d
Customizing User Credentials
If you wish to set the credentials for these users on your own, you have to create these Secrets before creating a custom resource. The below example shows how to create the three required user accounts prior to creating a custom resource. Note that if you omit any of these Secrets, the Postgres Operator will create it on its own.
# this variable is the name of the cluster being created
pgo_cluster_name=hippo
# this variable is the namespace the cluster is being deployed into
cluster_namespace=pgo
# this is the superuser secret
kubectl create secret generic -n "${cluster_namespace}" "${pgo_cluster_name}-postgres-secret" \
--from-literal=username=postgres \
--from-literal=password=Supersecurepassword*
# this is the replication user secret
kubectl create secret generic -n "${cluster_namespace}" "${pgo_cluster_name}-primaryuser-secret" \
--from-literal=username=primaryuser \
--from-literal=password=Anothersecurepassword*
# this is the standard user secret
kubectl create secret generic -n "${cluster_namespace}" "${pgo_cluster_name}-hippo-secret" \
--from-literal=username=hippo \
--from-literal=password=Moresecurepassword*
kubectl label secrets -n "${cluster_namespace}" "${pgo_cluster_name}-postgres-secret" "pg-cluster=${pgo_cluster_name}"
kubectl label secrets -n "${cluster_namespace}" "${pgo_cluster_name}-primaryuser-secret" "pg-cluster=${pgo_cluster_name}"
kubectl label secrets -n "${cluster_namespace}" "${pgo_cluster_name}-hippo-secret" "pg-cluster=${pgo_cluster_name}"
Create a PostgreSQL Cluster With Backups in S3
A frequent use case is to create a PostgreSQL cluster with S3 or a S3-like storage system for storing backups. This requires adding a Secret that contains the S3 key and key secret for your account, and adding some additional information into the custom resource.
Step 1: Create the pgBackRest S3 Secrets
As mentioned above, it is necessary to create a Secret containing the S3 key and key secret that will allow a user to create backups in S3.
The below code will help you set up this Secret.
# this variable is the name of the cluster being created
pgo_cluster_name=hippo
# this variable is the namespace the cluster is being deployed into
cluster_namespace=pgo
# the following variables are your S3 key and key secret
backrest_s3_key=yours3key
backrest_s3_key_secret=yours3keysecret
kubectl -n "${cluster_namespace}" create secret generic "${pgo_cluster_name}-backrest-repo-config" \
--from-literal="aws-s3-key=${backrest_s3_key}" \
--from-literal="aws-s3-key-secret=${backrest_s3_key_secret}"
unset backrest_s3_key
unset backrest_s3_key_secret
Step 2: Create the PostgreSQL Cluster
With the Secrets in place. It is now time to create the PostgreSQL cluster.
The below manifest references the Secrets created in the previous step to add a
custom resource to the pgclusters.crunchydata.com custom resource definition.
There are some additions in this example specifically for storing backups in S3.
# this variable is the name of the cluster being created
export pgo_cluster_name=hippo
# this variable is the namespace the cluster is being deployed into
export cluster_namespace=pgo
# the following variables store the information for your S3 cluster. You may
# need to adjust them for your actual settings
export backrest_s3_bucket=your-bucket
export backrest_s3_endpoint=s3.region-name.amazonaws.com
export backrest_s3_region=region-name
cat <<-EOF > "${pgo_cluster_name}-pgcluster.yaml"
apiVersion: crunchydata.com/v1
kind: Pgcluster
metadata:
annotations:
current-primary: ${pgo_cluster_name}
labels:
crunchy-pgha-scope: ${pgo_cluster_name}
deployment-name: ${pgo_cluster_name}
name: ${pgo_cluster_name}
pg-cluster: ${pgo_cluster_name}
pgo-version: 4.7.16
pgouser: admin
name: ${pgo_cluster_name}
namespace: ${cluster_namespace}
spec:
BackrestStorage:
accessmode: ReadWriteMany
matchLabels: ""
name: ""
size: 1G
storageclass: ""
storagetype: dynamic
supplementalgroups: ""
PrimaryStorage:
accessmode: ReadWriteMany
matchLabels: ""
name: ${pgo_cluster_name}
size: 1G
storageclass: ""
storagetype: dynamic
supplementalgroups: ""
ReplicaStorage:
accessmode: ReadWriteMany
matchLabels: ""
name: ""
size: 1G
storageclass: ""
storagetype: dynamic
supplementalgroups: ""
annotations: {}
backrestStorageTypes:
- s3
backrestS3Bucket: ${backrest_s3_bucket}
backrestS3Endpoint: ${backrest_s3_endpoint}
backrestS3Region: ${backrest_s3_region}
backrestS3URIStyle: ""
backrestS3VerifyTLS: ""
ccpimage: crunchy-postgres-ha
ccpimageprefix: registry.developers.crunchydata.com/crunchydata
ccpimagetag: ubi8-13.16-4.7.16
clustername: ${pgo_cluster_name}
database: ${pgo_cluster_name}
exporterport: "9187"
limits: {}
name: ${pgo_cluster_name}
pgDataSource:
restoreFrom: ""
restoreOpts: ""
pgbadgerport: "10000"
pgoimageprefix: registry.developers.crunchydata.com/crunchydata
podAntiAffinity:
default: preferred
pgBackRest: preferred
pgBouncer: preferred
port: "5432"
tolerations: []
user: hippo
userlabels:
pgo-version: 4.7.16
EOF
kubectl apply -f "${pgo_cluster_name}-pgcluster.yaml"
Create a PostgreSQL Cluster With Backups in GCS
A frequent use case is to create a PostgreSQL cluster with Google Cloud Storage (GCS) for storing backups. This requires adding a Secret that contains the GCS key for your account, and adding some additional information into the custom resource.
Step 1: Create the pgBackRest GCS Secrets
As mentioned above, it is necessary to create a Secret containing the GCS key. This is a file that you can download from Google.
The below code will help you set up this Secret.
# this variable is the name of the cluster being created
pgo_cluster_name=hippo
# this variable is the namespace the cluster is being deployed into
cluster_namespace=pgo
# this variable is your GCS credential
backrest_gcs_key=/path/to/your/gcs/credential.json
kubectl -n "${cluster_namespace}" create secret generic "${pgo_cluster_name}-backrest-repo-config" \
--from-file="gcs-key=${backrest_gcs_key}"
unset backrest_gcs_key
Step 2: Create the PostgreSQL Cluster
With the Secrets in place. It is now time to create the PostgreSQL cluster.
The below manifest references the Secrets created in the previous step to add a
custom resource to the pgclusters.crunchydata.com custom resource definition.
There are some additions in this example specifically for storing backups in
GCS.
# this variable is the name of the cluster being created
export pgo_cluster_name=hippo
# this variable is the namespace the cluster is being deployed into
export cluster_namespace=pgo
# the following variables store the information for your S3 cluster. You may
# need to adjust them for your actual settings
export backrest_gcs_bucket=your-bucket
cat <<-EOF > "${pgo_cluster_name}-pgcluster.yaml"
apiVersion: crunchydata.com/v1
kind: Pgcluster
metadata:
annotations:
current-primary: ${pgo_cluster_name}
labels:
crunchy-pgha-scope: ${pgo_cluster_name}
deployment-name: ${pgo_cluster_name}
name: ${pgo_cluster_name}
pg-cluster: ${pgo_cluster_name}
pgo-version: 4.7.16
pgouser: admin
name: ${pgo_cluster_name}
namespace: ${cluster_namespace}
spec:
BackrestStorage:
accessmode: ReadWriteMany
matchLabels: ""
name: ""
size: 1G
storageclass: ""
storagetype: dynamic
supplementalgroups: ""
PrimaryStorage:
accessmode: ReadWriteMany
matchLabels: ""
name: ${pgo_cluster_name}
size: 1G
storageclass: ""
storagetype: dynamic
supplementalgroups: ""
ReplicaStorage:
accessmode: ReadWriteMany
matchLabels: ""
name: ""
size: 1G
storageclass: ""
storagetype: dynamic
supplementalgroups: ""
annotations: {}
backrestStorageTypes:
- gcs
backrestGCSBucket: ${backrest_gcs_bucket}
ccpimage: crunchy-postgres-ha
ccpimageprefix: registry.developers.crunchydata.com/crunchydata
ccpimagetag: ubi8-13.16-4.7.16
clustername: ${pgo_cluster_name}
database: ${pgo_cluster_name}
exporterport: "9187"
limits: {}
name: ${pgo_cluster_name}
pgDataSource:
restoreFrom: ""
restoreOpts: ""
pgbadgerport: "10000"
pgoimageprefix: registry.developers.crunchydata.com/crunchydata
podAntiAffinity:
default: preferred
pgBackRest: preferred
pgBouncer: preferred
port: "5432"
tolerations: []
user: hippo
userlabels:
pgo-version: 4.7.16
EOF
kubectl apply -f "${pgo_cluster_name}-pgcluster.yaml"
Create a PostgreSQL Cluster with TLS
There are three items that are required to enable TLS in your PostgreSQL clusters:
- A CA certificate
- A TLS private key
- A TLS certificate
It is possible create a PostgreSQL cluster with TLS using a custom resource workflow with the prerequisite of ensuring the above three items are created.
For a detailed explanation for how TLS works with the PostgreSQL Operator, please see the TLS tutorial.
TLS can be added to an existing cluster, also long as there are values for tls.caSecret and tls.tlsSecret.
Step 1: Create TLS Secrets
There are two Secrets that need to be created:
- A Secret containing the certificate authority (CA). You may only need to create this Secret once, as a CA certificate can be shared amongst your clusters.
- A Secret that contains the TLS private key & certificate.
This assumes that you have already generated your TLS certificates where the CA is named ca.crt and the server key and certificate are named server.key and server.crt respectively.
Substitute the correct values for your environment into the environmental variables in the example below:
# this variable is the name of the cluster being created
export pgo_cluster_name=hippo
# this variable is the namespace the cluster is being deployed into
export cluster_namespace=pgo
# this is the local path to where you stored the CA and server key and certificate
export cluster_tls_asset_path=/path/to
# create the CA secret. if this already exists, it's OK if it fails
kubectl create secret generic postgresql-ca -n "${cluster_namespace}" \
--from-file="ca.crt=${cluster_tls_asset_path}/ca.crt"
# create the server key/certificate secret
kubectl create secret tls "${pgo_cluster_name}-tls-keypair" -n "${cluster_namespace}" \
--cert="${cluster_tls_asset_path}/server.crt" \
--key="${cluster_tls_asset_path}/server.key"
Step 2: Create the PostgreSQL Cluster
The below example uses the Secrets created in the previous step and creates a TLS-enabled PostgreSQL cluster. Additionally, this example sets the tlsOnly attribute to true, which requires all TCP connections to occur over TLS:
# this variable is the name of the cluster being created
export pgo_cluster_name=hippo
# this variable is the namespace the cluster is being deployed into
export cluster_namespace=pgo
cat <<-EOF > "${pgo_cluster_name}-pgcluster.yaml"
apiVersion: crunchydata.com/v1
kind: Pgcluster
metadata:
annotations:
current-primary: ${pgo_cluster_name}
labels:
crunchy-pgha-scope: ${pgo_cluster_name}
deployment-name: ${pgo_cluster_name}
name: ${pgo_cluster_name}
pg-cluster: ${pgo_cluster_name}
pgo-version: 4.7.16
pgouser: admin
name: ${pgo_cluster_name}
namespace: ${cluster_namespace}
spec:
BackrestStorage:
accessmode: ReadWriteMany
matchLabels: ""
name: ""
size: 1G
storageclass: ""
storagetype: dynamic
supplementalgroups: ""
PrimaryStorage:
accessmode: ReadWriteMany
matchLabels: ""
name: ${pgo_cluster_name}
size: 1G
storageclass: ""
storagetype: dynamic
supplementalgroups: ""
ReplicaStorage:
accessmode: ReadWriteMany
matchLabels: ""
name: ""
size: 1G
storageclass: ""
storagetype: dynamic
supplementalgroups: ""
annotations: {}
ccpimage: crunchy-postgres-ha
ccpimageprefix: registry.developers.crunchydata.com/crunchydata
ccpimagetag: ubi8-13.16-4.7.16
clustername: ${pgo_cluster_name}
database: ${pgo_cluster_name}
exporterport: "9187"
limits: {}
name: ${pgo_cluster_name}
pgDataSource:
restoreFrom: ""
restoreOpts: ""
pgbadgerport: "10000"
pgoimageprefix: registry.developers.crunchydata.com/crunchydata
podAntiAffinity:
default: preferred
pgBackRest: preferred
pgBouncer: preferred
port: "5432"
tls:
caSecret: postgresql-ca
tlsSecret: ${pgo_cluster_name}-tls-keypair
tlsOnly: true
user: hippo
userlabels:
pgo-version: 4.7.16
EOF
kubectl apply -f "${pgo_cluster_name}-pgcluster.yaml"
Modify a Cluster
There following modification operations are supported on the
pgclusters.crunchydata.com custom resource definition:
Modify Resource Requests & Limits
Modifying the resources, limits, backrestResources, backrestLimits,
pgBouncer.resources, or pgbouncer.limits will cause the PostgreSQL Operator
to apply the new values to the affected Deployments.
For example, if we wanted to make a memory request of 512Mi for the hippo
cluster created in the previous example, we could do the following:
# this variable is the name of the cluster being created
export pgo_cluster_name=hippo
# this variable is the namespace the cluster is being deployed into
export cluster_namespace=pgo
kubectl edit pgclusters.crunchydata.com -n "${cluster_namespace}" "${pgo_cluster_name}"
This will open up your editor. Find the resources block, and have it read as
the following:
resources:
memory: 256Mi
The PostgreSQL Operator will respond and modify the PostgreSQL instances to request 256Mi of memory.
Be careful when editing these values for a variety of reasons, mainly that modifying these values will cause the Pods to restart, which in turn will create potential downtime events. It’s best to modify the values for a deployment group together and not mix and match, i.e.
- PostgreSQL instances:
resources,limits - pgBackRest:
backrestResources,backrestLimits - pgBouncer:
pgBouncer.resources,pgBouncer.limits
Scale
Once you have created a PostgreSQL cluster, you may want to add a replica to
create a high-availability environment. Replicas are added and removed using the
pgreplicas.crunchydata.com custom resource definition. Each replica must have
a unique name, e.g. hippo-rpl1 could be one unique replica for a PostgreSQL
cluster.
Using the above example cluster, hippo, let’s add a replica called
hippo-rpl1 using the configuration below. Be sure to change the
replicastorage block to match the storage configuration for your environment:
# this variable is the name of the cluster being created
export pgo_cluster_name=hippo
# this helps to name the replica, in this case "rpl1"
export pgo_cluster_replica_suffix=rpl1
# this variable is the namespace the cluster is being deployed into
export cluster_namespace=pgo
cat <<-EOF > "${pgo_cluster_name}-${pgo_cluster_replica_suffix}-pgreplica.yaml"
apiVersion: crunchydata.com/v1
kind: Pgreplica
metadata:
labels:
name: ${pgo_cluster_name}-${pgo_cluster_replica_suffix}
pg-cluster: ${pgo_cluster_name}
pgouser: admin
name: ${pgo_cluster_name}-${pgo_cluster_replica_suffix}
namespace: ${cluster_namespace}
spec:
clustername: ${pgo_cluster_name}
name: ${pgo_cluster_name}-${pgo_cluster_replica_suffix}
replicastorage:
accessmode: ReadWriteMany
matchLabels: ""
name: ${pgo_cluster_name}-${pgo_cluster_replica_suffix}
size: 1G
storageclass: ""
storagetype: dynamic
supplementalgroups: ""
tolerations: []
userlabels:
pgo-version: 4.7.16
EOF
kubectl apply -f "${pgo_cluster_name}-${pgo_cluster_replica_suffix}-pgreplica.yaml"
Add this time, removing a replica must be handled through the pgo client.
Resize PVC
PGO lets you resize the PVCs that the Operator manages, e.g. the Postgres data directory, pgBackRest, the WAL volume, etc. The PVC can be resized so long as the following conditions are met:
- The Storage Class supports resizing.
- The new size of the PVC is larger than the old size.
The following sections explain how the different PVC resizing operations work and how you can resize the PVCs.
Resize the PostgreSQL Cluster PVC
To resize the PVC that stores the PostgreSQL data directory across the entire
cluster, you will need to edit the size attribute of the PrimaryStorage
section of the pgclusters.crunchydata.com custom resource.
The PVC resize process for a cluster uses a rolling update to apply the size changes. During the process, each Deployment is scaled down and back to allow for the PVC resize to take effect.
Resize the pgBackRest PVC
To resize the PVC that stores the backups managed by pgBackRest, you will need to
edit the size attribute of the BackrestStorage section of the
pgclusters.crunchydata.com custom resource.
The Postgres Operator will apply the PVC size change and scale the pgBackRest Deployment down and back up.
Resize a single PostgreSQL instance / read-only replica
To resize the PVC for a read-only replica, you can edit the size attribute
of the ReplicaStorage portion of the pgreplicas.crunchydata.com custom
resource.
Note that if a subsequent action resizes the PVCs for all of the instances in a Postgres cluster and that new PVC size is larger than the specific instance size that is set, then the instance PVC is also resized.
The Postgres Operator will apply the PVC size change and scale the instance Deployment down and back up.
Resize a WAL PVC
To resize the optional PVC that can be used to store WAL archives, you can edit
the size attribute of the WALStorage section of the
pgclusters.crunchydata.com custom resource.
The PVC resize process for a cluster uses a rolling update to apply the size changes. During the process, each Deployment is scaled down and back up to allow for the PVC resize to take effect.
Resize the pgAdmin 4 PVC
If you have deployed pgAdmin 4 and
need to resize its PVC, you can edit the size attribute of the PGAdmin
section of the pgclusters.crunchydata.com custom resource.
The PVC resize process for a cluster uses a rolling update to apply the size changes. During the process, the pgAdmin 4 Deployment is scaled down and back up to allow for the PVC resize to take effect.
Monitoring
To enable the monitoring
(aka metrics) sidecar using the crunchy-postgres-exporter container, you need
to set the exporter attribute in pgclusters.crunchydata.com custom resource.
Add a Tablespace
Tablespaces can be added during the lifetime of a PostgreSQL cluster (tablespaces can be removed as well, but for a detailed explanation as to how, please see the Tablespaces section).
To add a tablespace, you need to add an entry to the tablespaceMounts section
of a custom entry, where the key is the name of the tablespace (unique to the
pgclusters.crunchydata.com custom resource entry) and the value is a storage
configuration as defined in the pgclusters.crunchydata.com section above.
For example, to add a tablespace named lake to our hippo cluster, we can
open up the editor with the following code:
# this variable is the name of the cluster being created
export pgo_cluster_name=hippo
# this variable is the namespace the cluster is being deployed into
export cluster_namespace=pgo
kubectl edit pgclusters.crunchydata.com -n "${cluster_namespace}" "${pgo_cluster_name}"
and add an entry to the tablespaceMounts block that looks similar to this,
with the addition of the correct storage configuration for your environment:
tablespaceMounts:
lake:
accessmode: ReadWriteMany
matchLabels: ""
size: 5Gi
storageclass: ""
storagetype: dynamic
supplementalgroups: ""
pgBouncer
pgBouncer is a PostgreSQL connection pooler and
state manager that can be useful for high-availability setups as well as
managing overall performance of a PostgreSQL cluster. A pgBouncer deployment for
a PostgreSQL cluster can be fully managed from a pgclusters.crunchydata.com
custom resource.
For example, to add a pgBouncer deployment to our hippo cluster with two
instances and a memory limit of 36Mi, you can edit the custom resource:
# this variable is the name of the cluster being created
export pgo_cluster_name=hippo
# this variable is the namespace the cluster is being deployed into
export cluster_namespace=pgo
kubectl edit pgclusters.crunchydata.com -n "${cluster_namespace}" "${pgo_cluster_name}"
And modify the pgBouncer block to look like this:
pgBouncer:
limits:
memory: 36Mi
replicas: 2
Likewise, to remove pgBouncer from a PostgreSQL cluster, you would set
replicas to 0:
pgBouncer:
replicas: 0
Start / Stop a Cluster
A PostgreSQL cluster can be start and stopped by toggling the shutdown
parameter in a pgclusters.crunchydata.com custom resource. Setting shutdown
to true will stop a PostgreSQL cluster, whereas a value of false will make
a cluster available. This affects all of the associated instances of a
PostgreSQL cluster.
Manage Annotations
Kubernetes Annotations
can be managed for PostgreSQL, pgBackRest, and pgBouncer Deployments, as well as
being able to apply Annotations across all three. This is done via the
annotations block in the pgclusters.crunchydata.com custom resource
definition. For example, to apply Annotations in the hippo cluster, some that
are global, some that are specific to each Deployment type, you could do the
following.
First, start editing the hippo custom resource:
# this variable is the name of the cluster being created
export pgo_cluster_name=hippo
# this variable is the namespace the cluster is being deployed into
export cluster_namespace=pgo
kubectl edit pgclusters.crunchydata.com -n "${cluster_namespace}" "${pgo_cluster_name}"
In the hippo specification, add the annotations block similar to this (note,
this explicitly shows that this is the spec block. Do not modify the
annotations block in the metadata section).
spec:
annotations:
global:
favorite: hippo
backrest:
chair: comfy
pgBouncer:
pool: swimming
postgres:
elephant: cool
Save your edits, and in a short period of time, you should see these annotations applied to the managed Deployments.
Manage Custom Labels
Several Kubernetes Labels are automatically applied by PGO to its managed objects. However, it is possible to apply your own custom labels to the objects that PGO manages for a Postgres cluster. These objects include:
- ConfigMaps
- Deployments
- Jobs
- Pods
- PVCs
- Secrets
- Services
The custom labels can be managed through the userlabels attribute on the
pgclusters.crunchydata.com custom resource spec.
For example, if I want to add a custom label to all of the objects within my
Postgres cluster with a key of favorite and a value of hippo, you would
apply the following to the spec:
spec:
userlabels:
favorite: hippo
Delete a PostgreSQL Cluster
A PostgreSQL cluster can be deleted by simply deleting the pgclusters.crunchydata.com resource.
It is possible to keep both the PostgreSQL data directory as well as the pgBackRest backup repository when using this method by setting the following annotations on the pgclusters.crunchydata.com custom resource:
keep-backups: indicates to keep the pgBackRest PVC when deleting the cluster.keep-data: indicates to keep the PostgreSQL data PVC when deleting the cluster.
PostgreSQL Operator Custom Resource Definitions
There are several PostgreSQL Operator Custom Resource Definitions (CRDs) that are installed in order for the PostgreSQL Operator to successfully function:
pgclusters.crunchydata.com: Stores information required to manage a PostgreSQL cluster. This includes things like the cluster name, what storage and resource classes to use, which version of PostgreSQL to run, information about how to maintain a high-availability cluster, etc.pgreplicas.crunchydata.com: Stores information required to manage the replicas within a PostgreSQL cluster. This includes things like the number of replicas, what storage and resource classes to use, special affinity rules, etc.pgtasks.crunchydata.com: A general purpose CRD that accepts a type of task that is needed to run against a cluster (e.g. take a backup) and tracks the state of said task through its workflow.pgpolicies.crunchydata.com: Stores a reference to a SQL file that can be executed against a PostgreSQL cluster. In the past, this was used to manage RLS policies on PostgreSQL clusters.
Below takes an in depth look for what each attribute does in a Custom Resource Definition, and how they can be used in the creation and update workflow.
Glossary
create: if an attribute is listed ascreate, it means it can affect what happens when a new Custom Resource is created.update: if an attribute is listed asupdate, it means it can affect the Custom Resource, and by extension the objects it manages, when the attribute is updated.
pgclusters.crunchydata.com
The pgclusters.crunchydata.com Custom Resource Definition is the fundamental
definition of a PostgreSQL cluster. Most attributes only affect the deployment
of a PostgreSQL cluster at the time the PostgreSQL cluster is created. Some
attributes can be modified during the lifetime of the PostgreSQL cluster and
make changes, as described below.
Specification (Spec)
| Attribute | Action | Description |
|---|---|---|
| annotations | create, update |
Specify Kubernetes Annotations that can be applied to the different deployments managed by the PostgreSQL Operator (PostgreSQL, pgBackRest, pgBouncer). For more information, please see the “Annotations Specification” below. |
| backrestConfig | create |
Optional references to pgBackRest configuration files |
| backrestLimits | create, update |
Specify the container resource limits that the pgBackRest repository should use. Follows the Kubernetes definitions of resource limits. |
| backrestRepoPath | create |
Optional reference to the location of the pgBackRest repository. |
| backrestResources | create, update |
Specify the container resource requests that the pgBackRest repository should use. Follows the Kubernetes definitions of resource requests. |
| backrestGCSBucket | create |
An optional parameter (unless you are using GCS for backup storage) that specifies the GCS bucket that pgBackRest should use. |
| backrestGCSEndpoint | create |
An optional parameter that specifies a GCS endpoint pgBackRest should use, if not using the default GCS endpoint. |
| backrestGCSKeyType | create |
An optional parameter that specifies a GCS key type that pgBackRest should use. Can be either service or token, and if not specified, pgBackRest will use service. |
| backrestS3Endpoint | create |
An optional parameter that specifies the S3 endpoint pgBackRest should use. |
| backrestS3Region | create |
An optional parameter that specifies a cloud region that pgBackRest should use. |
| backrestS3URIStyle | create |
An optional parameter that specifies if pgBackRest should use the path or host S3 URI style. |
| backrestS3VerifyTLS | create |
An optional parameter that specifies if pgBackRest should verify the TLS endpoint. |
| BackrestStorage | create |
A specification that gives information about the storage attributes for the pgBackRest repository, which stores backups and archives, of the PostgreSQL cluster. For details, please see the Storage Specification section below. This is required. |
| backrestStorageTypes | create |
An optional parameter that takes an array of different repositories types that can be used to store pgBackRest backups. Choices are posix and s3. If nothing is specified, it defaults to posix. (local, equivalent to posix, is available for backwards compatibility). |
| ccpimage | create |
The name of the PostgreSQL container image to use, e.g. crunchy-postgres-ha or crunchy-postgres-ha-gis. |
| ccpimageprefix | create |
If provided, the image prefix (or registry) of the PostgreSQL container image, e.g. registry.developers.crunchydata.com/crunchydata. The default is to use the image prefix set in the PostgreSQL Operator configuration. |
| ccpimagetag | create |
The tag of the PostgreSQL container image to use, e.g. ubi8-13.16-4.7.16. |
| clustername | create |
The name of the PostgreSQL cluster, e.g. hippo. This is used to group PostgreSQL instances (primary, replicas) together. |
| customconfig | create |
If specified, references a custom ConfigMap to use when bootstrapping a PostgreSQL cluster. For the shape of this file, please see the section on Custom Configuration |
| database | create |
The name of a database that the PostgreSQL user can log into after the PostgreSQL cluster is created. |
| disableAutofail | create, update |
If set to true, disables the high availability capabilities of a PostgreSQL cluster. By default, every cluster can have high availability if there is at least one replica. |
| exporter | create,update |
If true, deploys the crunchy-postgres-exporter sidecar for metrics collection |
| exporterLimits | create, update |
Specify the container resource limits that the crunchy-postgres-exporter sidecar uses when it is deployed with a PostgreSQL instance. Follows the Kubernetes definitions of resource limits. |
| exporterport | create |
If Exporter is true, then this specifies the port that the metrics sidecar runs on (e.g. 9187) |
| exporterResources | create, update |
Specify the container resource requests that the crunchy-postgres-exporter sidecar uses when it is deployed with a PostgreSQL instance. Follows the Kubernetes definitions of resource requests. |
| limits | create, update |
Specify the container resource limits that the PostgreSQL cluster should use. Follows the Kubernetes definitions of resource limits. |
| name | create |
The name of the PostgreSQL instance that is the primary. On creation, this should be set to be the same as ClusterName. |
| nodeAffinity | create |
Sets the node affinity rules for the PostgreSQL cluster and associated PostgreSQL instances. Can be overridden on a per-instance (pgreplicas.crunchydata.com) basis. Please see the Node Affinity Specification section below. |
| passwordType | create, update |
If set, provides the Postgres password type that is used for creating Postgres users that are managed by PGO. Can be either md5 or scram-sha-256. |
| pgBadger | create,update |
If true, deploys the crunchy-pgbadger sidecar for query analysis. |
| pgbadgerport | create |
If the PGBadger label is set, then this specifies the port that the pgBadger sidecar runs on (e.g. 10000) |
| pgBouncer | create, update |
If specified, defines the attributes to use for the pgBouncer connection pooling deployment that can be used in conjunction with this PostgreSQL cluster. Please see the specification defined below. |
| pgDataSource | create |
Used to indicate if a PostgreSQL cluster should bootstrap its data from a pgBackRest repository. This uses the PostgreSQL Data Source Specification, described below. |
| pgoimageprefix | create |
If provided, the image prefix (or registry) of any PostgreSQL Operator images that are used for jobs, e.g. registry.developers.crunchydata.com/crunchydata. The default is to use the image prefix set in the PostgreSQL Operator configuration. |
| podAntiAffinity | create |
A required section. Sets the pod anti-affinity rules for the PostgreSQL cluster and associated deployments. Please see the Pod Anti-Affinity Specification section below. |
| policies | create |
If provided, a comma-separated list referring to pgpolicies.crunchydata.com.Spec.Name that should be run once the PostgreSQL primary is first initialized. |
| port | create |
The port that PostgreSQL will run on, e.g. 5432. |
| ReplicaStorage | create |
A specification that gives information about the storage attributes for any replicas in the PostgreSQL cluster. For details, please see the Storage Specification section below. This will likely be changed in the future based on the nature of the high-availability system, but presently it is still required that you set it. It is recommended you use similar settings to that of PrimaryStorage. |
| replicas | create |
The number of replicas to create after a PostgreSQL primary is first initialized. This only works on create; to scale a cluster after it is initialized, please use the pgo scale command. |
| resources | create, update |
Specify the container resource requests that the PostgreSQL cluster should use. Follows the Kubernetes definitions of resource requests. |
| serviceType | create, update |
Sets the Kubernetes Service type to use for the cluster. If not set, defaults to ClusterIP. |
| shutdown | create, update |
If set to true, indicates that a PostgreSQL cluster should shutdown. If set to false, indicates that a PostgreSQL cluster should be up and running. |
| standby | create, update |
If set to true, indicates that the PostgreSQL cluster is a “standby” cluster, i.e. is in read-only mode entirely. Please see Kubernetes Multi-Cluster Deployments for more information. |
| syncReplication | create |
If set to true, specifies the PostgreSQL cluster to use synchronous replication. |
| tablespaceMounts | create,update |
Lists any tablespaces that are attached to the PostgreSQL cluster. Tablespaces can be added at a later time by updating the TablespaceMounts entry, but they cannot be removed. Stores a map of information, with the key being the name of the tablespace, and the value being a Storage Specification, defined below. |
| tls | create, update |
Defines the attributes for enabling TLS for a PostgreSQL cluster. See TLS Specification below. |
| tlsOnly | create,update |
If set to true, requires client connections to use only TLS to connect to the PostgreSQL database. |
| tolerations | create,update |
Any array of Kubernetes Tolerations. Please refer to the Kubernetes documentation for how to set this field. |
| user | create |
The name of the PostgreSQL user that is created when the PostgreSQL cluster is first created. |
| userlabels | create,update |
A set of key-value string pairs that are used as a sort of “catch-all” as well as a way to add custom labels to clusters. |
Storage Specification
The storage specification is a spec that defines attributes about the storage to be used for a particular function of a PostgreSQL cluster (e.g. a primary instance or for the pgBackRest backup repository). The below describes each attribute and how it works.
| Attribute | Action | Description |
|---|---|---|
| accessmode | create |
The name of the Kubernetes Persistent Volume Access Mode to use. |
| matchLabels | create |
Only used with StorageType of create, used to match a particular subset of provisioned Persistent Volumes. |
| name | create |
Only needed for PrimaryStorage in pgclusters.crunchydata.com.Used to identify the name of the PostgreSQL cluster. Should match ClusterName. |
| size | create, update |
The size of the Persistent Volume Claim (PVC). Must use a Kubernetes resource value, e.g. 20Gi. |
| storageclass | create |
The name of the Kubernetes StorageClass to use. |
| storagetype | create |
Set to create if storage is provisioned (e.g. using hostpath). Set to dynamic if using a dynamic storage provisioner, e.g. via a StorageClass. |
| supplementalgroups | create |
If provided, a comma-separated list of group IDs to use in case it is needed to interface with a particular storage system. Typically used with NFS or hostpath storage. |
Node Affinity Specification
Sets the node affinity
for the PostgreSQL cluster and associated deployments. Follows the Kubernetes standard format for setting node affinity, including preferred and required node affinity.
To set node affinity for a PostgreSQL cluster, you will need to modify the default attribute in the node affinity specification. As mentioned above, the values that default accepts match what Kubernetes uses for node affinity.
For a detailed explanation for node affinity works. Please see the high-availability documentation.
| Attribute | Action | Description |
|---|---|---|
| default | create |
The default pod anti-affinity to use for all PostgreSQL instances managed in a given PostgreSQL cluster. Can be overridden on a per-instance basis with the pgreplicas.crunchydata.com custom resource. |
Pod Anti-Affinity Specification
Sets the pod anti-affinity for the PostgreSQL cluster and associated deployments. Each attribute can contain one of the following values:
requiredpreferred(which is also the recommended default)disabled
For a detailed explanation for how this works. Please see the high-availability documentation.
| Attribute | Action | Description |
|---|---|---|
| default | create |
The default pod anti-affinity to use for all Pods managed in a given PostgreSQL cluster. |
| pgBackRest | create |
If set to a value that differs from Default, specifies the pod anti-affinity to use for just the pgBackRest repository. |
| pgBouncer | create |
If set to a value that differs from Default, specifies the pod anti-affinity to use for just the pgBouncer Pods. |
PostgreSQL Data Source Specification
This specification is used when one wants to bootstrap the data in a PostgreSQL cluster from a pgBackRest repository. This can be a pgBackRest repository that is attached to an active PostgreSQL cluster or is kept around to be used for spawning new PostgreSQL clusters.
| Attribute | Action | Description |
|---|---|---|
| restoreFrom | create |
The name of a PostgreSQL cluster, active or former, that will be used for bootstrapping the data of a new PostgreSQL cluster. |
| restoreOpts | create |
Additional pgBackRest restore options that can be used as part of the bootstrapping operation, for example, point-in-time-recovery options. |
TLS Specification
The TLS specification makes a reference to the various secrets that are required to enable TLS in a PostgreSQL cluster. For more information on how these secrets should be structured, please see Enabling TLS in a PostgreSQL Cluster.
| Attribute | Action | Description |
|---|---|---|
| caSecret | create, update |
A reference to the name of a Kubernetes Secret that specifies a certificate authority for the PostgreSQL cluster to trust. |
| replicationTLSSecret | create, update |
A reference to the name of a Kubernetes TLS Secret that contains a keypair for authenticating the replication user. Must be used with CASecret and TLSSecret. |
| tlsSecret | create, update |
A reference to the name of a Kubernetes TLS Secret that contains a keypair that is used for the PostgreSQL instance to identify itself and perform TLS communications with PostgreSQL clients. Must be used with CASecret. |
pgBouncer Specification
The pgBouncer specification defines how a pgBouncer deployment can be deployed alongside the PostgreSQL cluster. pgBouncer is a PostgreSQL connection pooler that can also help manage connection state, and is helpful to deploy alongside a PostgreSQL cluster to help with failover scenarios too.
| Attribute | Action | Description |
|---|---|---|
| limits | create, update |
Specify the container resource limits that the pgBouncer Pods should use. Follows the Kubernetes definitions of resource limits. |
| replicas | create, update |
The number of pgBouncer instances to deploy. Must be set to at least 1 to deploy pgBouncer. Setting to 0 removes an existing pgBouncer deployment for the PostgreSQL cluster. |
| resources | create, update |
Specify the container resource requests that the pgBouncer Pods should use. Follows the Kubernetes definitions of resource requests. |
| serviceType | create, update |
Sets the Kubernetes Service type to use for the cluster. If not set, defaults to the ServiceType set for the PostgreSQL cluster. |
| tlsSecret | create |
A reference to the name of a Kubernetes TLS Secret that contains a keypair that is used for the pgBouncer instance to identify itself and perform TLS communications with PostgreSQL clients. Must be used with the parent Spec TLSSecret and CASecret. |
Annotations Specification
The pgcluster.crunchydata.com specification contains a block that allows for
custom Annotations
to be applied to the Deployments that are managed by the PostgreSQL Operator,
including:
- PostgreSQL
- pgBackRest
- pgBouncer
This also includes the option to apply Annotations globally across the three different deployment groups.
| Attribute | Action | Description |
|---|---|---|
| backrest | create, update |
Specify annotations that are only applied to the pgBackRest deployments |
| global | create, update |
Specify annotations that are applied to the PostgreSQL, pgBackRest, and pgBouncer deployments |
| pgBouncer | create, update |
Specify annotations that are only applied to the pgBouncer deployments |
| postgres | create, update |
Specify annotations that are only applied to the PostgreSQL deployments |
pgreplicas.crunchydata.com
The pgreplicas.crunchydata.com Custom Resource Definition contains information
pertaning to the structure of PostgreSQL replicas associated within a PostgreSQL
cluster. All of the attributes only affect the replica when it is created.
Specification (Spec)
| Attribute | Action | Description |
|---|---|---|
| clustername | create |
The name of the PostgreSQL cluster, e.g. hippo. This is used to group PostgreSQL instances (primary, replicas) together. |
| name | create |
The name of this PostgreSQL replica. It should be unique within a ClusterName. |
| nodeAffinity | create |
Sets the node affinity rules for this PostgreSQL instance. Follows the Kubernetes standard format for setting node affinity. |
| replicastorage | create |
A specification that gives information about the storage attributes for any replicas in the PostgreSQL cluster. For details, please see the Storage Specification section in the pgclusters.crunchydata.com description. This will likely be changed in the future based on the nature of the high-availability system, but presently it is still required that you set it. It is recommended you use similar settings to that of PrimaryStorage. |
| serviceType | create, update |
Sets the Kubernetes Service type to use for this particular instance. If not set, defaults to the value in the related pgclusters.crunchydata.com custom resource. |
| userlabels | create |
A set of key-value string pairs that are used as a sort of “catch-all” as well as a way to add custom labels to clusters. This will disappear at some point. |
| tolerations | create,update |
Any array of Kubernetes Tolerations. Please refer to the Kubernetes documentation for how to set this field. |