Disaster Recovery
When using the PostgreSQL Operator, the answer to the question “do you take backups of your database” is automatically “yes!”
The PostgreSQL Operator uses the open source pgBackRest backup and restore utility that is designed for working with databases that are many terabytes in size. As described in the Provisioning section, pgBackRest is enabled by default as it permits the PostgreSQL Operator to automate some advanced as well as convenient behaviors, including:
- Efficient provisioning of new replicas that are added to the PostgreSQL cluster
- Preventing replicas from falling out of sync from the PostgreSQL primary by allowing them to replay old WAL logs
- Allowing failed primaries to automatically and efficiently heal using the “delta restore” feature
- Serving as the basis for the cluster cloning feature
- …and of course, allowing for one to take full, differential, and incremental backups and perform full and point-in-time restores
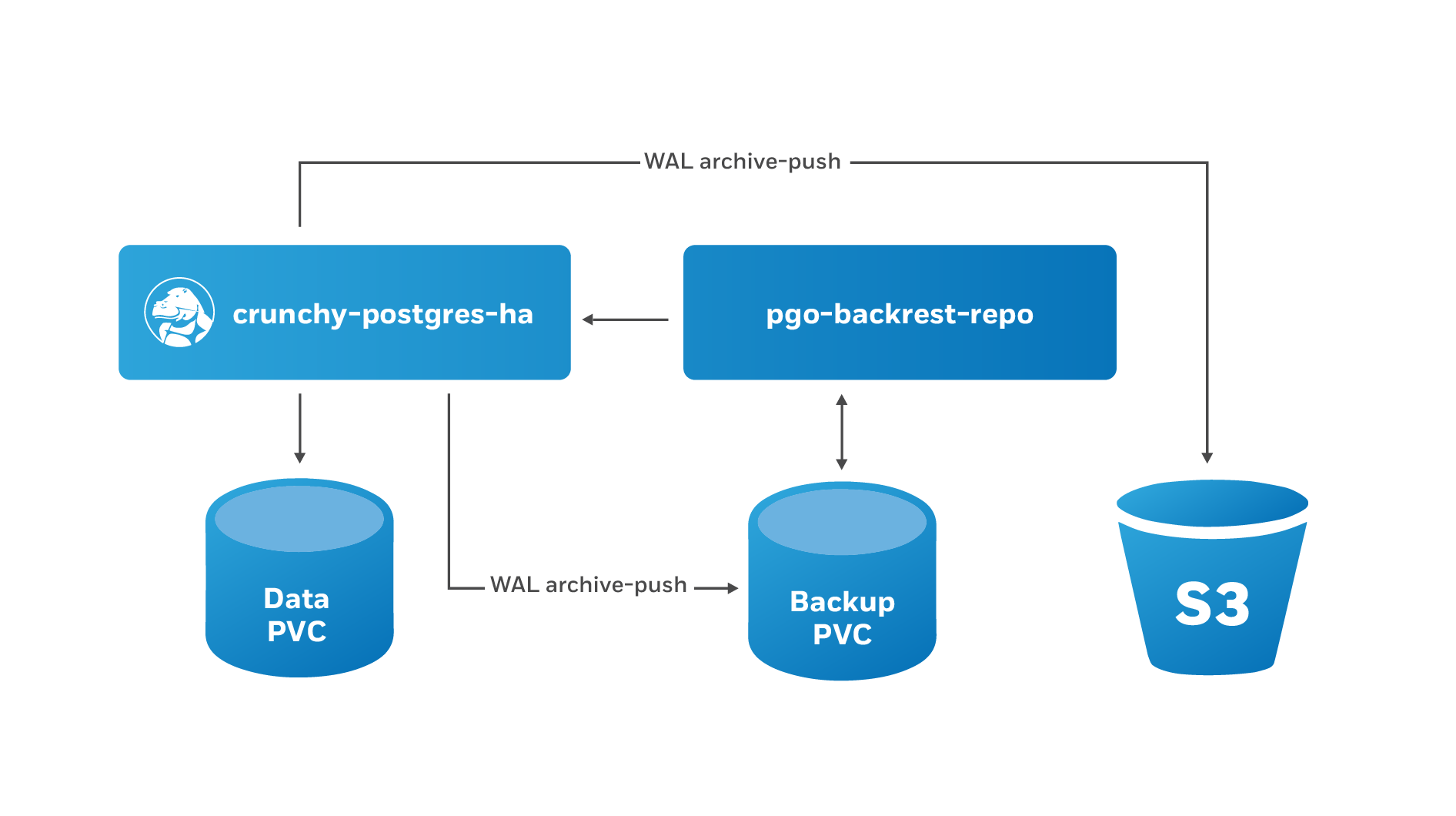
The PostgreSQL Operator leverages a pgBackRest repository to facilitate the usage of the pgBackRest features in a PostgreSQL cluster. When a new PostgreSQL cluster is created, it simultaneously creates a pgBackRest repository as described in the Provisioning section.
At PostgreSQL cluster creation time, you can specify a specific Storage Class for the pgBackRest repository. Additionally, you can also specify the type of pgBackRest repository that can be used, including:
posix: Uses the storage that is provided by the Kubernetes cluster’s Storage Class that you selects3: Use Amazon S3 or an object storage system that uses the S3 protocolgcs: Use Google Cloud Storage (GCS)posix,s3: Use both the storage that is provided by the Kubernetes cluster’s Storage Class that you select AND Amazon S3 (or equivalent object storage system that uses the S3 protocol)posix,gcs: Use both the storage that is provided by the Kubernetes cluster’s Storage Class that you select and Google Cloud Storage (GCS)
The pgBackRest repository consists of the following Kubernetes objects:
- A Deployment
- A Secret that contains information that is specific to the PostgreSQL cluster that it is deployed with (e.g. SSH keys, AWS S3 keys, etc.)
- A Service
The PostgreSQL primary is automatically configured to use the
pgbackrest archive-push and push the write-ahead log (WAL) archives to the
correct repository.
Backups
Backups can be taken with the pgo backup command
The PostgreSQL Operator supports three types of pgBackRest backups:
- Full (
full): A full backup of all the contents of the PostgreSQL cluster - Differential (
diff): A backup of only the files that have changed since the last full backup - Incremental (
incr): A backup of only the files that have changed since the last full or differential backup
By default, pgo backup will attempt to take an incremental (incr) backup
unless otherwise specified.
For example, to specify a full backup:
pgo backup hacluster --backup-opts="--type=full"The PostgreSQL Operator also supports setting pgBackRest retention policies as well for backups. For example, to take a full backup and to specify to only keep the last 7 backups:
pgo backup hacluster --backup-opts="--type=full --repo1-retention-full=7"Restores
The PostgreSQL Operator supports the ability to perform a full restore on a PostgreSQL cluster as well as a point-in-time-recovery. There are two types of ways to restore a cluster:
- Restore to a new cluster using the
--restore-fromflag in thepgo create clustercommand. - Restore in-place using the
pgo restorecommand. Note that this is destructive.
NOTE: Ensure you are backing up your PostgreSQL cluster regularly, as this will help expedite your restore times. The next section will cover scheduling regular backups.
The following explains how to perform restores based on the restoration method you chose.
Restore to a New Cluster
Restoring to a new PostgreSQL cluster allows one to take a backup and create a new PostgreSQL cluster that can run alongside an existing PostgreSQL cluster. There are several scenarios where using this technique is helpful:
- Creating a copy of a PostgreSQL cluster that can be used for other purposes. Another way of putting this is “creating a clone.”
- Restore to a point-in-time and inspect the state of the data without affecting the current cluster
and more.
Restoring to a new cluster can be accomplished using the pgo create cluster
command with several flags:
--restore-from: specifies the name of a PostgreSQL cluster (either one that is active, or a former cluster whose pgBackRest repository still exists) to restore from.--restore-from-namespace(optional): the namespace of the PostgreSQL cluster specified using--restore-from(the namespace of the cluster being created is utilized if a namespace is not specified using this option)--restore-opts: used to specify additional options, similar to the ones that are passed intopgbackrest restore.
One can copy an entire PostgreSQL cluster into a new cluster with a command as simple as the one below:
pgo create cluster newcluster --restore-from oldcluster
To perform a point-in-time-recovery, you have to pass in the pgBackRest --type
and --target options, where --type indicates the type of recovery to
perform, and --target indicates the point in time to recover to:
pgo create cluster newcluster \
--restore-from oldcluster \
--restore-opts "--type=time --target='2019-12-31 11:59:59.999999+00'"
Note that when using this method, the PostgreSQL Operator can only restore one
cluster from each pgBackRest repository at a time. Using the above example, one
can only perform one restore from oldcluster at a given time. Additionally,
if the cluster being utilized for restore is in another namespace than the
cluster being created, the proper namespace can be specified using the
--restore-from-namespace option.
When using the restore to a new cluster method, the PostgreSQL Operator takes the following actions:
- After running the normal cluster creation tasks, the PostgreSQL Operator creates a “bootstrap” job that performs a pgBackRest restore to the newly created PVC.
- The PostgreSQL Operator kicks off the new PostgreSQL cluster, which enters into recovery mode until it has recovered to a specified point-in-time or finishes replaying all available write-ahead logs.
- When this is done, the PostgreSQL cluster performs its regular operations when starting up.
Restore in-place
Restoring a PostgreSQL cluster in-place is a destructive action that will
perform a recovery on your existing data directory. This is accomplished using
the pgo restore
command.
pgo restore lets you specify the point at which you want to restore your
database using the --pitr-target flag.
When the PostgreSQL Operator issues a restore, the following actions are taken on the cluster:
- The PostgreSQL Operator disables the “autofail” mechanism so that no failovers will occur during the restore.
- Any replicas that may be associated with the PostgreSQL cluster are destroyed
- A new Persistent Volume Claim (PVC) is allocated using the specifications
provided for the primary instance. This may have been set with the
--storage-classflag when the cluster was originally created - A Kubernetes Job is created that will perform a pgBackRest restore operation to the newly allocated PVC.
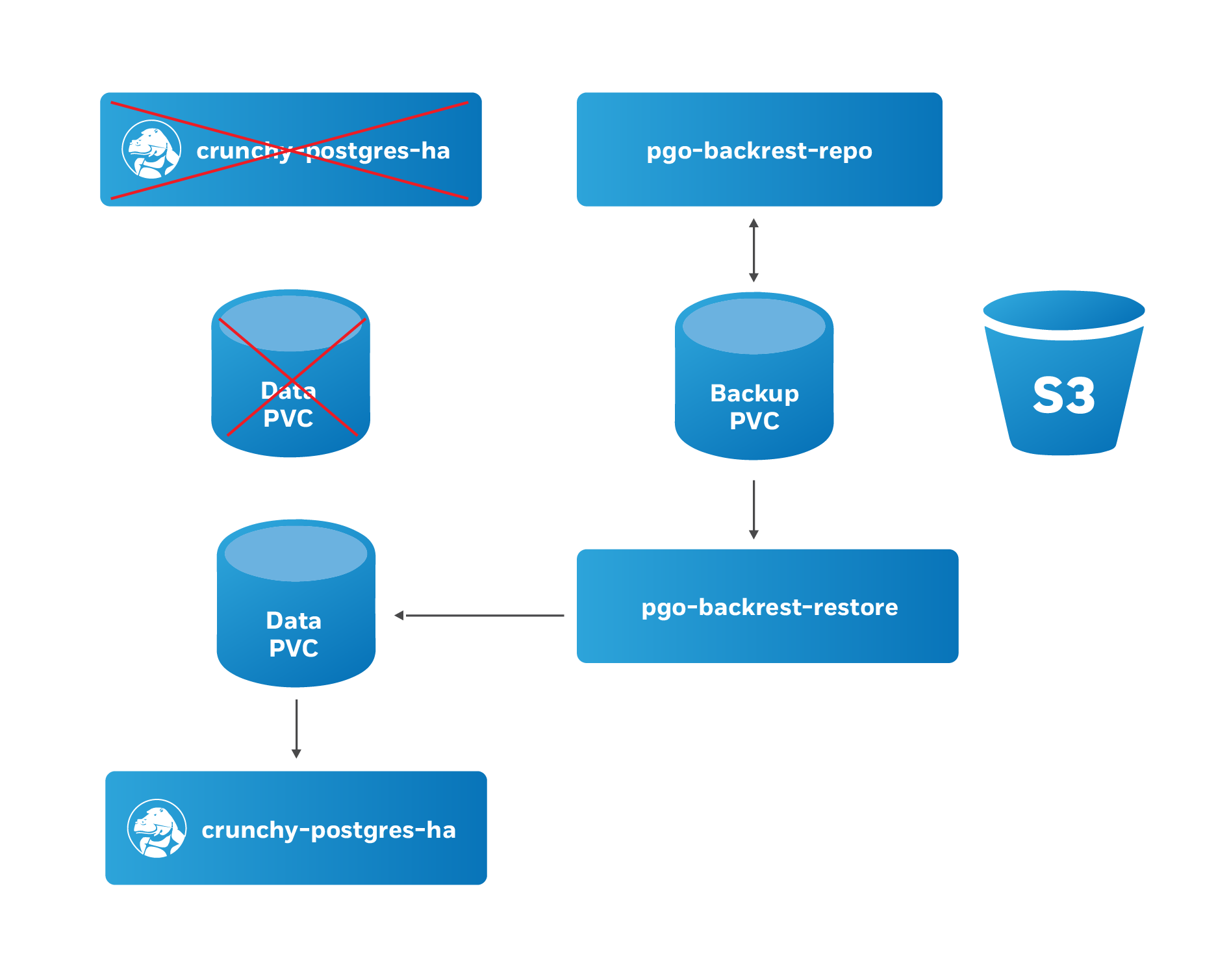
- When restore Job successfully completes, a new Deployment for the PostgreSQL cluster primary instance is created. A recovery is then issued to the specified point-in-time, or if it is a full recovery, up to the point of the latest WAL archive in the repository.
- Once the PostgreSQL primary instance is available, the PostgreSQL Operator will take a new, full backup of the cluster.
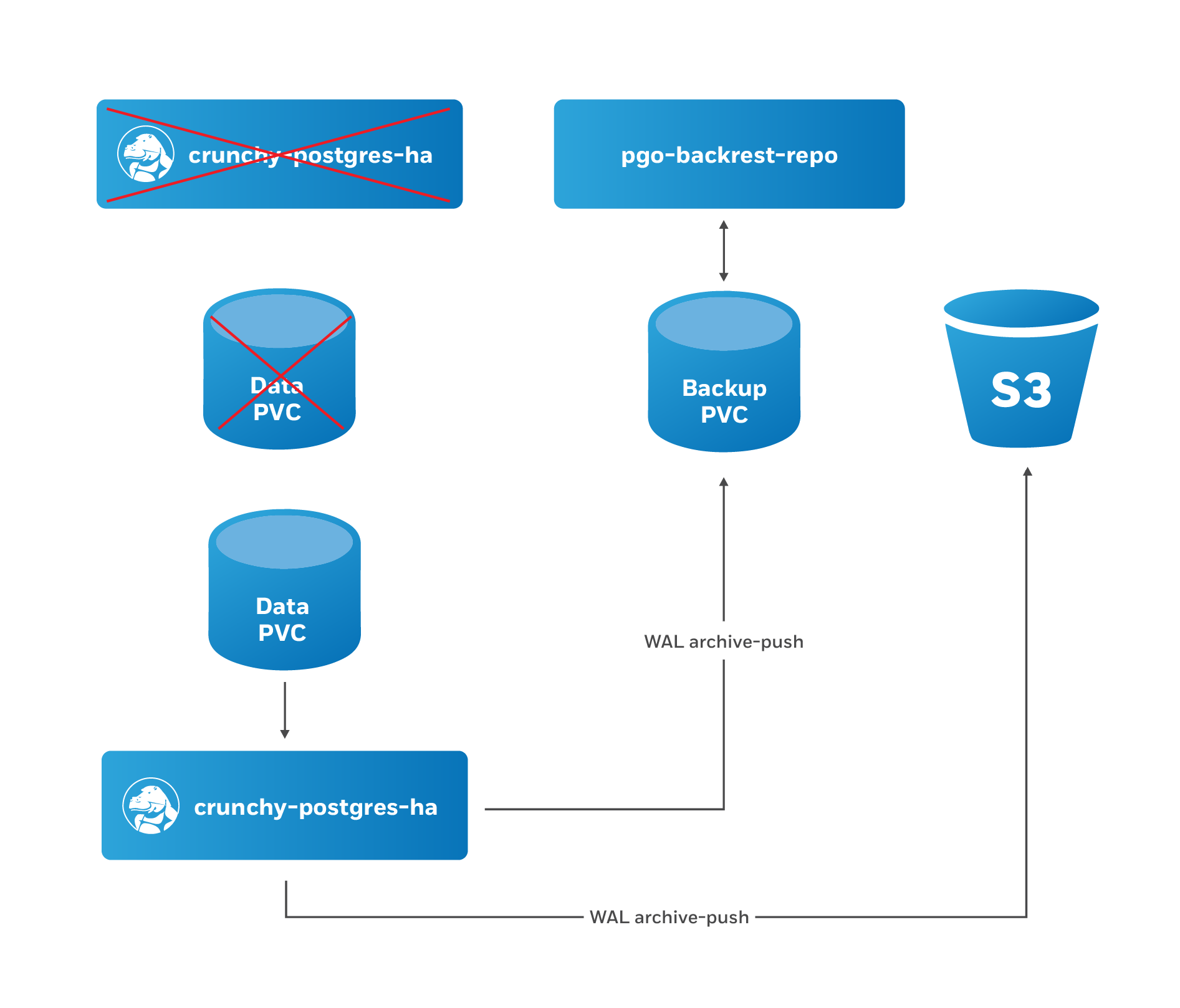
At this point, the PostgreSQL cluster has been restored. However, you will need to re-enable autofail if you would like your PostgreSQL cluster to be highly-available. You can re-enable autofail with this command:
pgo update cluster hacluster --enable-autofailScheduling Backups
Any effective disaster recovery strategy includes having regularly scheduled backups. The PostgreSQL Operator enables this through its scheduling sidecar that is deployed alongside the Operator.
The PostgreSQL Operator Scheduler is essentially a cron server that will run jobs that it is specified. Schedule commands use the cron syntax to set up scheduled tasks.
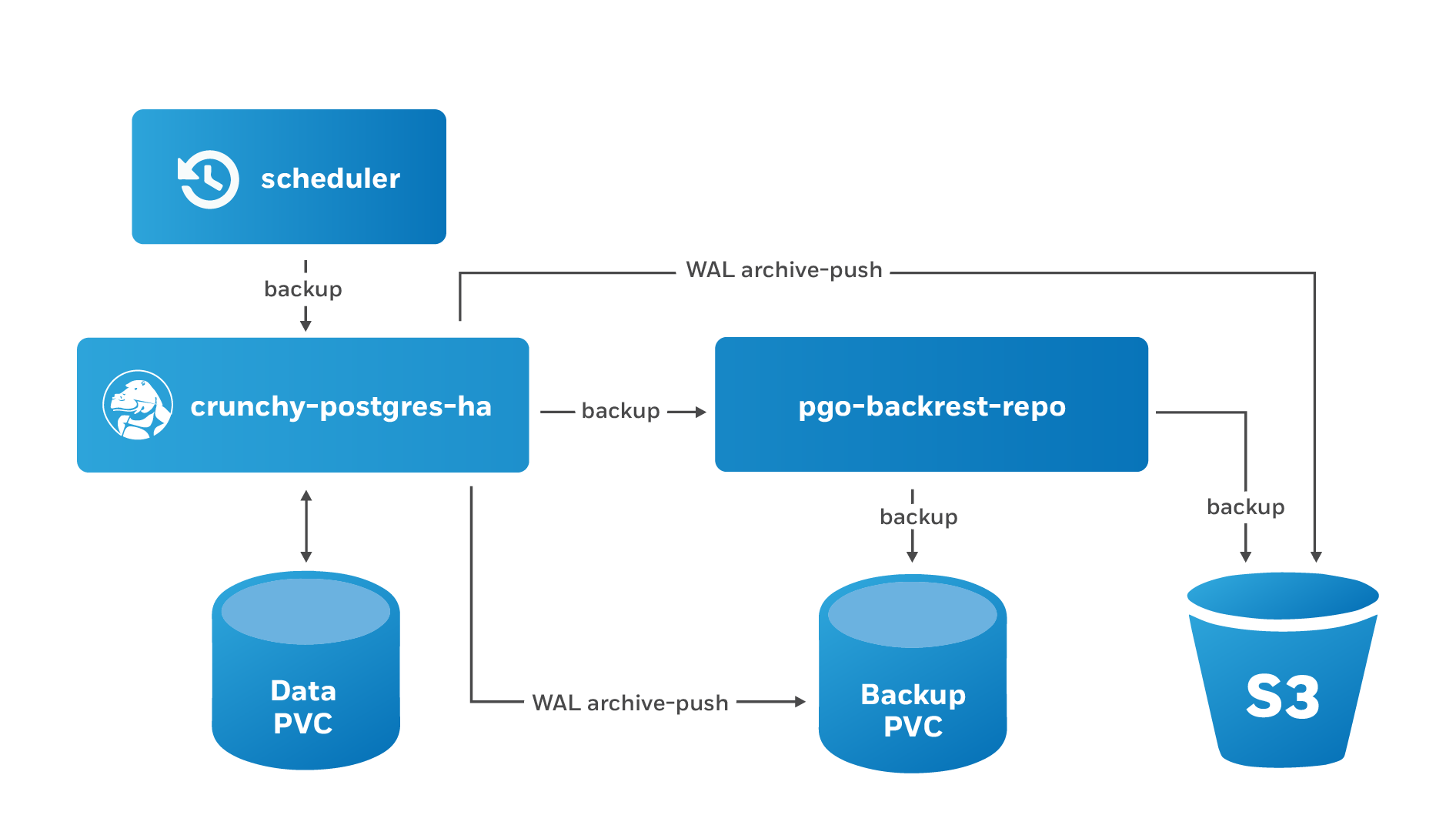
For example, to schedule a full backup once a day at 1am, the following command can be used:
pgo create schedule hacluster --schedule="0 1 * * *" \
--schedule-type=pgbackrest --pgbackrest-backup-type=fullTo schedule an incremental backup once every 3 hours:
pgo create schedule hacluster --schedule="0 */3 * * *" \
--schedule-type=pgbackrest --pgbackrest-backup-type=incrSetting Backup Retention Policies
Unless specified, pgBackRest will keep an unlimited number of backups. As part
of your regularly scheduled backups, it is encouraged for you to set a retention
policy. This can be accomplished using the --repo1-retention-full for full
backups and --repo1-retention-diff for differential backups via the
--schedule-opts parameter.
For example, using the above example of taking a nightly full backup, you can specify a policy of retaining 21 backups using the following command:
pgo create schedule hacluster --schedule="0 1 * * *" \
--schedule-type=pgbackrest --pgbackrest-backup-type=full \
--schedule-opts="--repo1-retention-full=21"Schedule Expression Format
Schedules are expressed using the following rules, which should be familiar to users of cron:
Field name | Mandatory? | Allowed values | Allowed special characters
---------- | ---------- | -------------- | --------------------------
Seconds | Yes | 0-59 | * / , -
Minutes | Yes | 0-59 | * / , -
Hours | Yes | 0-23 | * / , -
Day of month | Yes | 1-31 | * / , - ?
Month | Yes | 1-12 or JAN-DEC | * / , -
Day of week | Yes | 0-6 or SUN-SAT | * / , - ?
Using S3
The PostgreSQL Operator integration with pgBackRest allows it to use the AWS S3 object storage system, as well as other object storage systems that implement the S3 protocol.
In order to enable S3 storage, it is helpful to provide some of the S3
information prior to deploying the PostgreSQL Operator, or updating the
pgo-config ConfigMap and restarting the PostgreSQL Operator pod.
First, you will need to add the proper S3 bucket name, AWS S3 endpoint and
the AWS S3 region to the Cluster section of the pgo.yaml
configuration file:
Cluster:
BackrestS3Bucket: my-postgresql-backups-example
BackrestS3Endpoint: s3.amazonaws.com
BackrestS3Region: us-east-1
BackrestS3URIStyle: host
BackrestS3VerifyTLS: trueThese values can also be set on a per-cluster basis with the
pgo create cluster command, i.e.:
--pgbackrest-s3-bucket- specifics the AWS S3 bucket that should be utilized--pgbackrest-s3-endpointspecifies the S3 endpoint that should be utilized--pgbackrest-s3-key- specifies the AWS S3 key that should be utilized--pgbackrest-s3-key-secret- specifies the AWS S3 key secret that should be utilized--pgbackrest-s3-region- specifies the AWS S3 region that should be utilized--pgbackrest-s3-uri-style- specifies whether “host” or “path” style URIs should be utilized--pgbackrest-s3-verify-tls- set this value to “true” to enable TLS verification
Sensitive information, such as the values of the AWS S3 keys and secrets, are stored in Kubernetes Secrets and are securely mounted to the PostgreSQL clusters.
To enable a PostgreSQL cluster to use S3, the --pgbackrest-storage-type on the
pgo create cluster command needs to be set to s3 or posix,s3.
Once configured, the pgo backup and pgo restore commands will work with S3
similarly to the above!
Using GCS
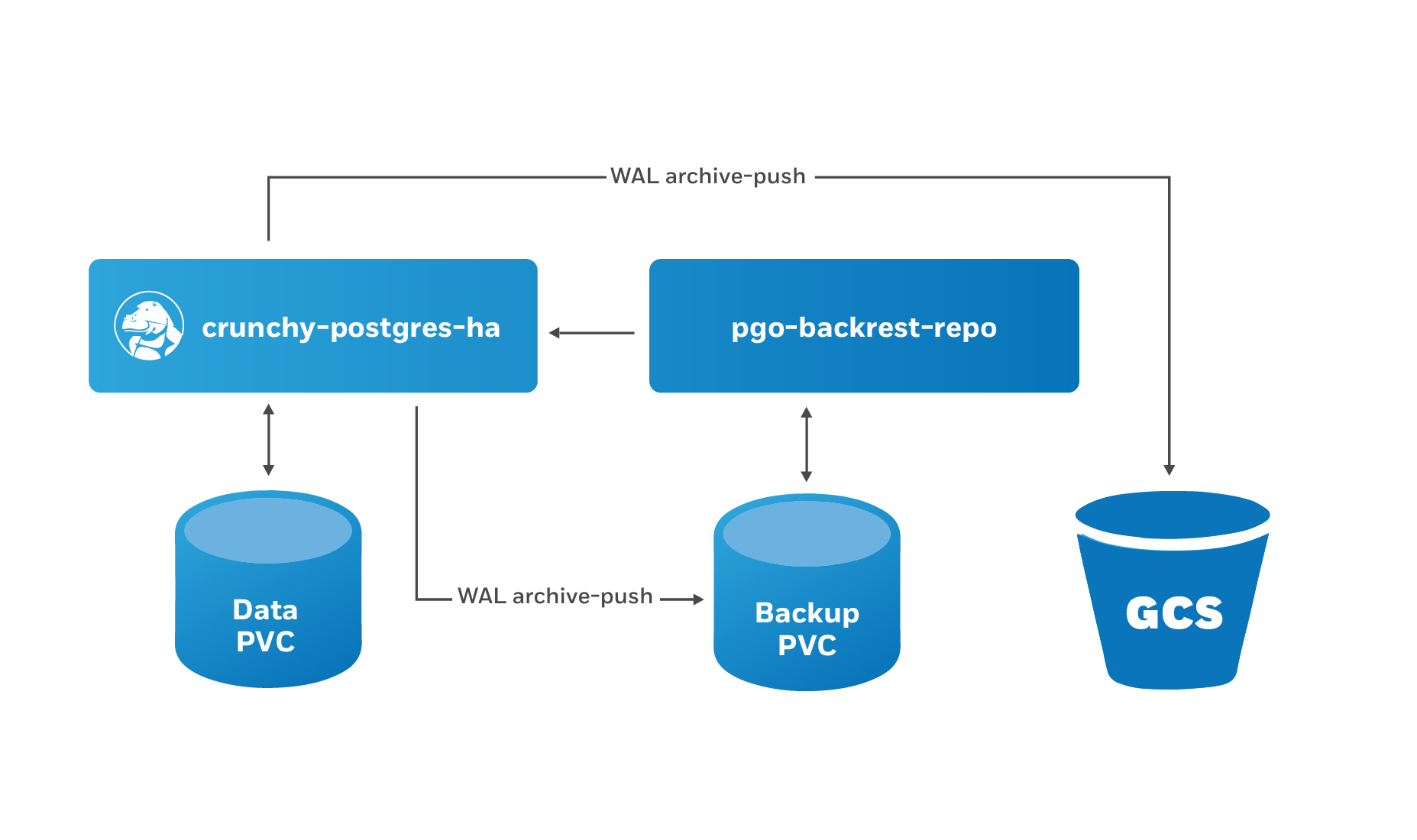
The PostgreSQL Operator integration with pgBackRest allows it to use the Google Cloud Storage (GCS) object storage system.
In order to enable GCS, it is helpful to provide some of the GCS
information prior to deploying PGO, the Postgres Operator, or updating the
pgo-config ConfigMap and restarting the Postgres Operator pod.
The easiest way to get started is by setting the GCS bucket name that you wish
to use with the Postgres Operator. You can do this by editing the Cluster
section of the pgo.yaml configuration file:
Cluster:
BackrestGCSBucket: my-postgresql-backups-exampleThese values can also be set on a per-cluster basis with the
pgo create cluster command. The two most important ones are:
--pgbackrest-gcs-bucket- specifics the GCS bucket that should be utilized. If not specified, the default bucket name that you set in thepgo.yamlconfiguration file will be used.--pgbackrest-gcs-key- A path to the GCS credential file on your local system. This will be added to the pgBackRest Secret.
There are some other options that are optional, but explained below for completeness:
--pgbackrest-gcs-endpointspecifies an alternative GCS endpoint.--pgbackrest-gcs-key-type- Eitherserviceortoken, defaults toservice.
As mentioned above, GCS keys are stored in Kubernetes Secrets and are securely mounted to PostgreSQL clusters.
To enable a PostgreSQL cluster to use GCS, the --pgbackrest-storage-type on the
pgo create cluster command needs to be set to gcs or posix,gcs.
Once configured, the pgo backup and pgo restore commands will work with GCS
similarly to the above!
Deleting a Backup
A backup can be deleted using the pgo delete backup
command. You must specify a specific backup to delete using the --target flag.
You can get the backup names from the
pgo show backup
command.
For example, using a PostgreSQL cluster called hippo, pretend there is an
example pgBackRest repository in the state shown after running the
pgo show backup hippo command:
cluster: hippo
storage type: posix
stanza: db
status: ok
cipher: none
db (current)
wal archive min/max (12-1)
full backup: 20201220-171801F
timestamp start/stop: 2020-12-20 17:18:01 +0000 UTC / 2020-12-20 17:18:10 +0000 UTC
wal start/stop: 000000010000000000000002 / 000000010000000000000002
database size: 31.3MiB, backup size: 31.3MiB
repository size: 3.8MiB, repository backup size: 3.8MiB
backup reference list:
incr backup: 20201220-171801F_20201220-171939I
timestamp start/stop: 2020-12-20 17:19:39 +0000 UTC / 2020-12-20 17:19:41 +0000 UTC
wal start/stop: 000000010000000000000005 / 000000010000000000000005
database size: 31.3MiB, backup size: 216.3KiB
repository size: 3.8MiB, repository backup size: 25.9KiB
backup reference list: 20201220-171801F
incr backup: 20201220-171801F_20201220-172046I
timestamp start/stop: 2020-12-20 17:20:46 +0000 UTC / 2020-12-20 17:23:29 +0000 UTC
wal start/stop: 00000001000000000000000A / 00000001000000000000000A
database size: 65.9MiB, backup size: 37.5MiB
repository size: 7.7MiB, repository backup size: 4.3MiB
backup reference list: 20201220-171801F, 20201220-171801F_20201220-171939I
full backup: 20201220-201305F
timestamp start/stop: 2020-12-20 20:13:05 +0000 UTC / 2020-12-20 20:13:15 +0000 UTC
wal start/stop: 00000001000000000000000F / 00000001000000000000000F
database size: 65.9MiB, backup size: 65.9MiB
repository size: 7.7MiB, repository backup size: 7.7MiB
backup reference list:
The backup targets can be found after the backup type, e.g. 20201220-171801F
or 20201220-171801F_20201220-172046I.
One can delete the oldest backup, in this case 20201220-171801F, by running
the following command:
pgo delete backup hippo --target=20201220-171801F
Verify the backup is deleted with pgo show backup hippo:
cluster: hippo
storage type: posix
stanza: db
status: ok
cipher: none
db (current)
wal archive min/max (12-1)
full backup: 20201220-201305F
timestamp start/stop: 2020-12-20 20:13:05 +0000 UTC / 2020-12-20 20:13:15 +0000 UTC
wal start/stop: 00000001000000000000000F / 00000001000000000000000F
database size: 65.9MiB, backup size: 65.9MiB
repository size: 7.7MiB, repository backup size: 7.7MiB
backup reference list:
(Note: this had the net effect of expiring all of the incremental backups associated with the full backup that as deleted. This is a feature of pgBackRest).