Setting up Exporters
The Linux instructions below use RHEL, but any Linux-based system should work. Crunchy Data customers can obtain Linux packages through the Crunchy Customer Portal; for Windows packages, contact Crunchy Data directly.
Installation
RPM installs
The following RPM packages are available to Crunchy Data customers through the Crunchy Customer Portal. After installing via these packages, continue reading at the Setup section.
Available Packages
| Package Name | Description |
|---|---|
| node_exporter | Base package for node_exporter |
| postgres_exporter | Base package for postgres_exporter |
| pgmonitor-pg##-extras | Crunchy optimized configurations for postgres_exporter. Note that each major version of PostgreSQL has its own extras package (pgmonitor-pg96-extras, pgmonitor-pg10-extras, etc) |
| pgmonitor-pg-common | Package containing postgres_exporter items common for all versions of postgres |
| pgmonitor-node_exporter-extras | Crunchy optimized configurations for node_exporter |
| pg_bloat_check | Package for pg_bloat_check script |
| pgbouncer_fdw | Package for the pgbouncer_fdw extension |
| blackbox_exporter | Package for the blackbox_exporter |
Non-RPM installs
For non-package installations on Linux, applications can be downloaded from their respective repositories:
| Library | |
|---|---|
| node_exporter | https://github.com/prometheus/node_exporter/releases |
| postgres_exporter | https://github.com/wrouesnel/postgres_exporter/releases |
| pg_bloat_check | https://github.com/keithf4/pg_bloat_check |
| pgbouncer_fdw | https://github.com/CrunchyData/pgbouncer_fdw |
| blackbox_exporter | https://github.com/prometheus/blackbox_exporter |
User and Configuration Directory Installation
You will need to create a user named ccp_monitoring which you can do with the following command:
sudo useradd -m -d /var/lib/ccp_monitoring ccp_monitoringConfiguration File Installation
All executables installed via the above releases are expected to be in the /usr/bin directory. A base node_exporter systemd file is expected to be in place already. An example one can be found here:
https://github.com/lest/prometheus-rpm/tree/master/node_exporter
A base blackbox_exporter systemd file is also expected to be in place. No examples are currently available.
The files contained in this repository are assumed to be installed in the following locations with the following names. In the instructions below, you should replace a double-hash (##) with the two-digit major version of PostgreSQL you are running (ex: 95, 96, 10, etc.).
node_exporter
The node_exporter data directory should be /var/lib/ccp_monitoring/node_exporter and owned by the ccp_monitoring user. You can set it up with:
sudo install -m 0700 -o ccp_monitoring -g ccp_monitoring -d /var/lib/ccp_monitoring/node_exporterThe following pgMonitor configuration files should be placed according to the following mapping:
| pgmonitor Configuration File | System Location |
|---|---|
| node/crunchy-node-exporter-service-el7.conf | /etc/systemd/system/node_exporter.service.d/crunchy-node-exporter-service-el7.conf |
| node/sysconfig.node_exporter | /etc/sysconfig/node_exporter |
postgres_exporter
The following pgMonitor configuration files should be placed according to the following mapping:
| pgMonitor Configuration File | System Location |
|---|---|
| crontab.txt | /etc/postgres_exporter/##/crontab.txt |
| postgres/crunchy_postgres_exporter@.service | /usr/lib/systemd/system/crunchy_postgres_exporter@.service |
| postgres/sysconfig.postgres_exporter_pg## | /etc/sysconfig/postgres_exporter_pg## |
| postgres/sysconfig.postgres_exporter_pg##_per_db | /etc/sysconfig/postgres_exporter_pg##_per_db |
| postgres/setup_pg##.sql | /etc/postgres_exporter/##/setup_pg##.sql |
| postgres/queries_*.yml | /etc/postgres_exporter/##/queries_*.yml |
| postgres/pgbackrest-info.sh | /usr/bin/pgbackrest-info.sh |
blackbox_exporter
The following pgMonitor configuration files should be placed according to the following mapping:
| pgMonitor Configuration File | System Location |
|---|---|
| blackbox/blackbox_exporter.sysconfig | /etc/sysconfig/blackbox_exporter |
| blackbox/crunchy-blackbox.yml | /etc/blackbox_exporter/crunchy-blackbox.yml |
Windows installs
The following Windows Server 2012R2 packages are available to Crunchy Data customers. After installing via these packages, continue reading at the Windows Server 2012R2 section.
Available Packages
| PACKAGE NAME | DESCRIPTION |
|---|---|
| pgMonitorclient#.#_Crunchy.win.x86_64.exe | Contains the needed metric exporters for monitoring the health of a PostgreSQL server. Contains both the WMI Exporter and the postgres_exporter. |
The client package is run on the PostgreSQL server(s) to be monitored. This includes the primary and all secondary servers.
Upgrading
- See the CHANGELOG for full details on both major & minor version upgrades.
Setup
Setup on RHEL or CentOS 7+
Service Configuration
The following files contain defaults that should enable the exporters to run effectively on your system for the purposes of using pgMonitor. You should take some time to review them.
If you need to modify them, see the notes in the files for more details and recommendations:
- /etc/systemd/system/node_exporter.service.d/crunchy-node-exporter-service-el7.conf
- /etc/sysconfig/node_exporter
- /etc/sysconfig/postgres_exporter_pg##
- /etc/sysconfig/postgres_exporter_pg##_per_db
Note that /etc/sysconfig/postgres_exporter_pg## & postgres_exporter_pg##_per_db are the default sysconfig files for monitoring the database running on the local socket at /var/run/postgresql and connect to the “postgres” database. If you’ve installed the pgMonitor setup to a different database, modify these files accordingly or make new ones. If you make new ones, ensure the service name you enable references this file (see the Enable Services section below ).
Database Configuration
General Configuration
First, make sure you have installed the PostgreSQL contrib modules. You can install them with the following command:
sudo yum install postgresql##-contribWhere ## corresponds to your current PostgreSQL version. For PostgreSQL 11 this would be:
sudo yum install postgresql11-contribYou will need to modify your postgresql.conf configuration file to tell PostgreSQL to load shared libraries. In the default setup, this file can be found at /var/lib/pgsql/##/data/postgresql.conf.
Modify your postgresql.conf configuration file to add the following shared libraries
shared_preload_libraries = 'pg_stat_statements,auto_explain'
You will need to restart your PostgreSQL instance for the change to take effect. Neither of the above extensions are used outside of the postgres database itself, but we find they are extremely useful to have loaded and available in the database when further diagnosis of issues is required.
For each database you are planning to monitor, you will need to run the following command as a PostgreSQL superuser:
CREATE EXTENSION pg_stat_statements;If you want the pg_stat_statements extension to be available in all newly created databases, you can run the following command as a PostgreSQL superuser:
psql -d template1 -c "CREATE EXTENSION pg_stat_statements;"Monitoring Setup
| Query File | Description |
|---|---|
| setup_pg##.sql | Creates ccp_monitoring role with all necessary grants. Creates all necessary database objects (functions, tables, etc) required for monitoring. |
| queries_bloat.yml | postgres_exporter query file to allow bloat monitoring. |
| queries_common.yml | postgres_exporter query file with minimal recommended queries that are common across all PG versions. |
| queries_per_db.yml | postgres_exporter query file with queries that gather per databse stats. WARNING: If your database has many tables this can greatly increase the storage requirements for your prometheus database. If necessary, edit the query to only gather tables you are interested in statistics for. The “PostgreSQL Details” and the “CRUD Details” Dashboards use these statistics. |
| queries_pg##.yml | postgres_exporter query file for queries that are specific to the given version of PostgreSQL. |
| queries_backrest.yml | postgres_exporter query file for monitoring pgBackRest backup status. By default, new backrest data is only collected every 10 minutes to avoid excessive load when there are large backup lists. See sysconfig file for exporter service to adjust this throttling. |
| queries_pgbouncer.yml | postgres_exporter query file for monitoring pgbouncer. |
| queries_pg_stat_statements_pg##.yml | postgres_exporter query file for specific pg_stat_statements metrics that are most useful for monitoring and trending. Only supported for PostgreSQL 10 and above. |
By default, there are two postgres_exporter services expected to be running as of pgMonitor 4.0 and higher. One connects to the default postgres database that most postgresql instances come with and is meant for collecting global metrics that are the same on all databases in the instance, for example connection and replication statistics. This service uses the sysconfig file postgres_exporter_pg##. Connect to this database and run the setup_pg##.sql script to install the required database objects for pgMonitor.
The second postgres_exporter service is used to collect per-database metrics and uses the sysconfig file postgres_exporter_pg##_per_db. By default it is set to also connect to the postgres database, but you can add as many additional connection strings to this service for each individual database that you want metrics for. Per-db metrics include things like table/index statistics and bloat. See the section below for monitorig multitple databases for how to do this.
Note that your pg_hba.conf will have to be configured to allow the ccp_monitoring system user to connect as the ccp_monitoring role to any database in the instance. As of version 4.0 of pg_monitor, the postgres_exporter service is set to connect via local socket, so passwordless local peer authentication is the expected default. If password-based authentication is required, we recommend using SCRAM authentication, which is supported as of version 0.7.x of postgres_exporter. See our blog post for more information on SCRAM - https://info.crunchydata.com/blog/how-to-upgrade-postgresql-passwords-to-scram
The common queries to all postgres versions are contained in queries_common.yml. Major version specific queries are contained in a relevantly named file. Queries for more specialized monitoring are contained in additional files.
postgres_exporter only takes a single yaml file as an argument for custom queries, so this requires concatinating the relevant files together. The sysconfig files for the service help with this concatination task and define the variable QUERY_FILE_LIST. Set this variable to a space delimited list of the full path names to all files that contain queries you want to be in the single file that postgres_exporter uses.
For example, to use just the common queries for PostgreSQL 9.6 modify the relevant sysconfig file and update QUERY_FILE_LIST.
QUERY_FILE_LIST="/etc/postgres_exporter/96/queries_common.yml /etc/postgres_exporter/96/queries_pg96.yml"As an another example, to include queries for PostgreSQL 10 as well as pgBackRest, modify the relevant sysconfig file and update QUERY_FILE_LIST:
QUERY_FILE_LIST="/etc/postgres_exporter/10/queries_common.yml /etc/postgres_exporter/10/queries_pg10.yml /etc/postgres_exporter/10/queries_backrest.yml"For replica servers, the setup is the same except that the setup_pg##.sql file does not need to be run since writes cannot be done there and it was already run on the primary.
Access Control: GRANT statements
The ccp_monitoring database role (created by running the “setup_pg##.sql” file above) must be allowed to connect to all databases in the cluster. To do this, run the following command to generate the necessary GRANT statements:
SELECT 'GRANT CONNECT ON DATABASE "' || datname || '" TO ccp_monitoring;'
FROM pg_database
WHERE datallowconn = true;This should generate one or more statements similar to the following:
GRANT CONNECT ON DATABASE "postgres" TO ccp_monitoring;Run these grant statements to then allow monitoring to connect.
Bloat setup
Run the script on the specific database(s) you will be for monitoring bloat in the cluster. See special note in crontab.txt concerning a superuser requirement for using this script
psql -d postgres -c "CREATE EXTENSION pgstattuple;"
/usr/bin/pg_bloat_check.py -c "host=localhost dbname=postgres user=postgres" --create_stats_table
psql -d postgres -c "GRANT SELECT,INSERT,UPDATE,DELETE,TRUNCATE ON bloat_indexes, bloat_stats, bloat_tables TO ccp_monitoring;"The /etc/postgres_exporter/##/crontab.txt file is meant to be a guide for how you setup the ccp_monitoring crontab. You should modify crontab entries to schedule your bloat check for off-peak hours. This script is meant to be run at most, once a week. Once a month is usually good enough for most databases as long as the results are acted upon quickly.
The script requires being run by a database superuser by default since it must be able to run a scan on every table. If you’d like to not run it as a superuser, you will have to create a new role that has read permissions on all tables in all schemas that are to be monitored for bloat. You can then change the user in the connection string option to the script.
Blackbox Exporter
The configuration file for the blackbox_exporter provided by pgMonitor (/etc/blackbox_exporter/crunchy-blackbox.yml) provides a probe for monitoring any IPv4 TCP port status. The actual target and port being monitored are controlled via the Prometheus target configuration system. Please see the pgMonitor Prometheus documentation for further details. If any additional Blackbox probes are desired, please see the upstream documentation.
PGBouncer
In order to monitor pgbouncer with pgMonitor, the pgbouncer_fdw maintained by CrunchyData is required. Please see its repository for full installation instructions. A package for this is available for Crunchy customers.
https://github.com/CrunchyData/pgbouncer_fdw
Once that is working, you should be able to add the queries_pgbouncer.yml file to the QUERY_FILE_LIST for the exporter that is monitoring the database where the FDW was installed.
Enable Services
sudo systemctl enable node_exporter
sudo systemctl start node_exporter
sudo systemctl status node_exporterIf you’ve installed the blackbox exporter:
sudo systemctl enable blackbox_exporter
sudo systemctl start blackbox_exporter
sudo systemctl status blackbox_exporter
To most easily allow the use of multiple postgres exporters, running multiple major versions of PostgreSQL, and to avoid maintaining many similar service files, a systemd template service file is used. The name of the sysconfig EnvironmentFile to be used by the service is passed as the value after the “@” and before “.service” in the service name. The default exporter’s sysconfig file is named “postgres_exporter_pg##” and tied to the major version of postgres that it was installed for. A similar EnvironmentFile exists for the per-db service. Be sure to replace the ## in the below commands first!
sudo systemctl enable crunchy-postgres-exporter@postgres_exporter_pg##
sudo systemctl start crunchy-postgres-exporter@postgres_exporter_pg##
sudo systemctl status crunchy-postgres-exporter@postgres_exporter_pg##
sudo systemctl enable crunchy-postgres-exporter@postgres_exporter_pg##_per_db
sudo systemctl start crunchy-postgres-exporter@postgres_exporter_pg##_per_db
sudo systemctl status crunchy-postgres-exporter@postgres_exporter_pg##_per_dbMonitoring multiple databases and/or running multiple postgres exporters (RHEL / CentOS)
Certain metrics are not cluster-wide, so multiple exporters must be run to collect all relevant metrics. As of v0.5.x of postgres_exporter, a single service can connect to multiple databases. As long as you’re using the same custom query file for all of those databases, only one additional exporter service is required and this comes with pgMonitor 4.0 and above by default. The queries_perdb.yml file contains these queries and the secondary exporter can use this file to collect those metrics and avoid duplicating cluster-wide metrics. Note that some other metrics are per database as well (Ex. bloat). You can then define multiple targets for that one job in Prometheus so that all the metrics are collected together for a single database instance. Note that the “setup*.sql” file does not need to be run on these additional databases if using the queries that pgMonitor comes with.
pgMonitor provides and recommends an example sysconfig file for this per-db exporter: sysconfig.postgres_exporter_pg##_per_db. If you’d like to create additional exporter services for different query files, just copy the existing ones and modify the relevant lines, mainly being the port, database name, and query file. The below example shows connecting to 3 databases in the same instance to collect their per-db metrics: postgres, mydb1, and mydb2.
OPT="--web.listen-address=0.0.0.0:9188 --extend.query-path=/etc/postgres_exporter/11/queries_per_db.yml"
DATA_SOURCE_NAME="postgresql:///postgres?host=/var/run/postgresql/&user=ccp_monitoring&sslmode=disable,postgresql:///mydb1?host=/var/run/postgresql/&user=ccp_monitoring&sslmode=disable,postgresql:///mydb2?host=/var/run/postgresql/&user=ccp_monitoring&sslmode=disable"
As was done with the exporter service that is collecting the global metrics, also modify the QUERY_LIST_FILE in the new sysconfig file to only collect per-db metrics
QUERY_FILE_LIST="/etc/postgres_exporter/11/queries_per_db.yml"
Since a systemd template is used for the postgres_exporter services, all you need to do is pass the sysconfig file name as part of the new service name.
sudo systemctl enable crunchy-postgres-exporter@postgres_exporter_pg11_per_db
sudo systemctl start cruncy-postgres-exporter@postgres_exporter_pg11_per_db
sudo systemctl status crunchy-postgres-exporter@postgres_exporter_pg11_per_db
Lastly, update the Prometheus auto.d target file to include the new exporter in the same job you already had running for this system
Windows Server 2012R2
Currently the Windows installers assume you are logged in as the local Administrator account, so please ensure to do so before attempting the following.
Install the WMI and PostgreSQL exporters by:
Find and launch the
pgMonitor_client_#.#_Crunchy.win.x86_64.exefile previously obtained from Crunchy Data. It will present you with the following screen: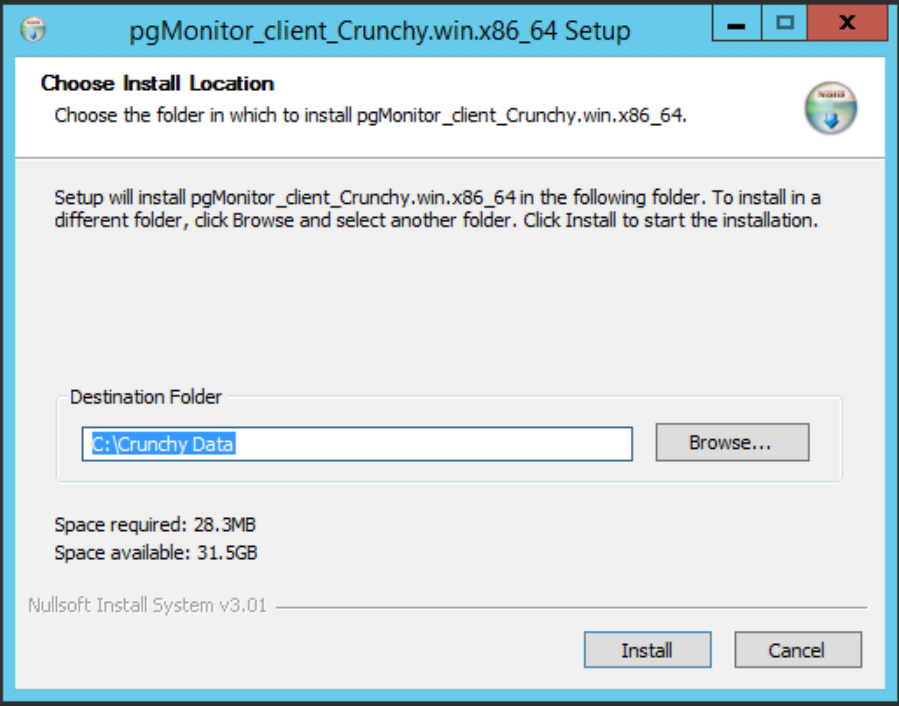
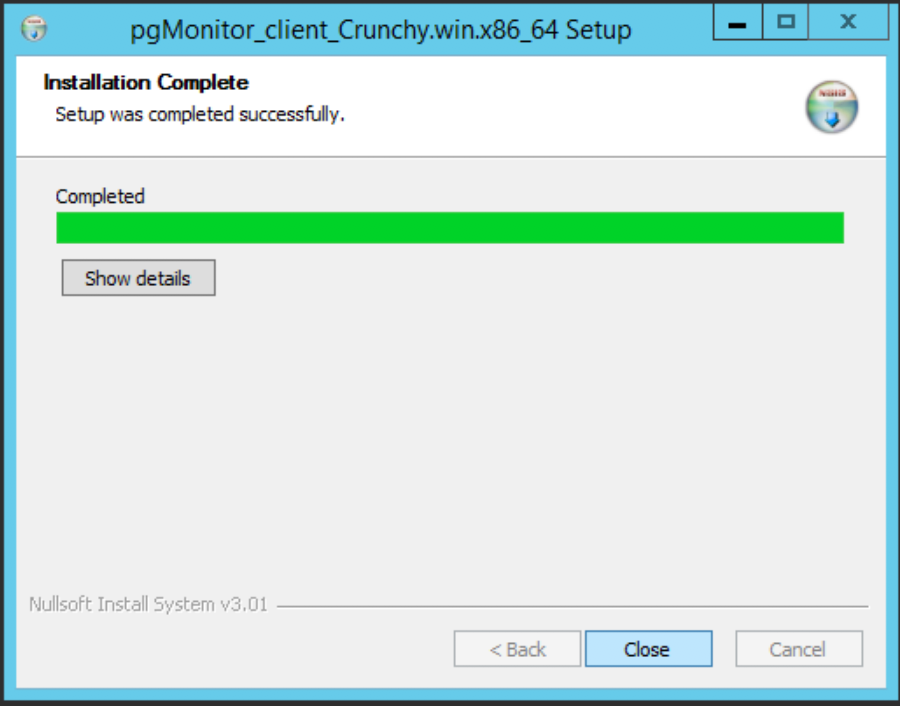
Adjust the desired installation path and click ‘Install’. The installer will run until you are eventually presented with this screen, where you can click ‘Close’:
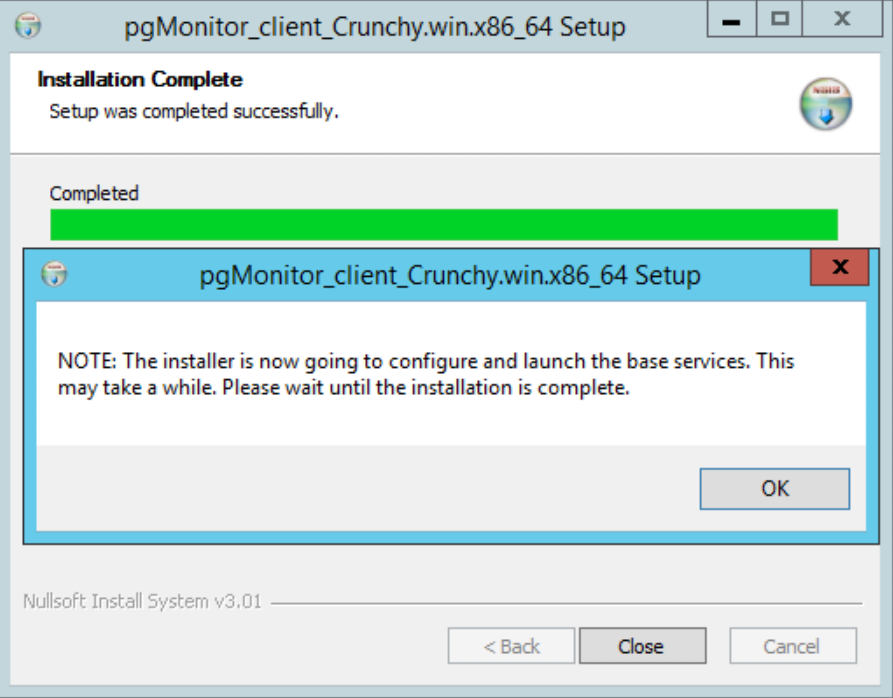
The installer will then launch the configuration utility:
You will then be prompted to configure the
postgres_exporter. Choose ‘Yes’ to do so: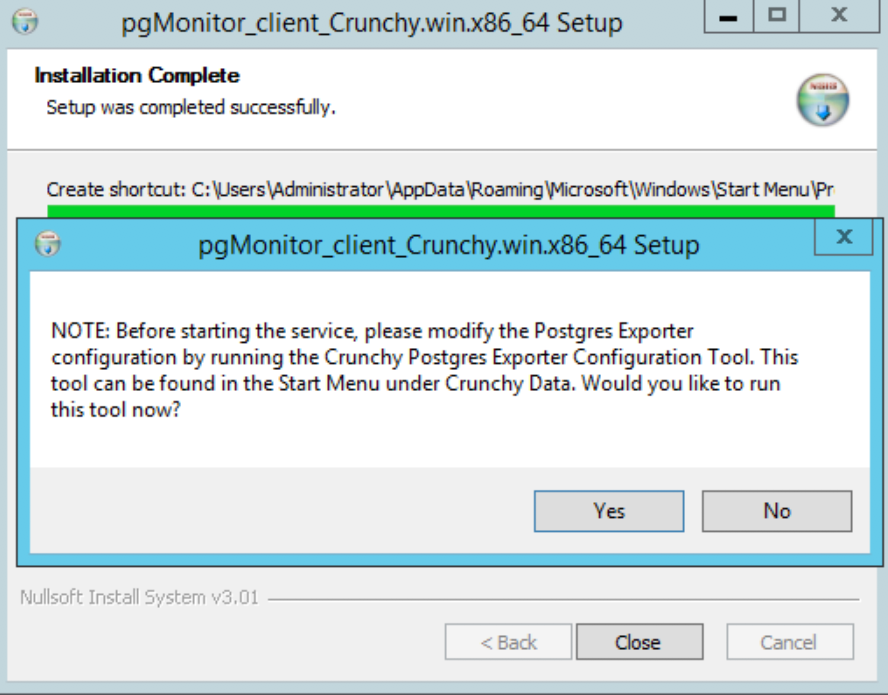
The configuration window will open. It first prompts you for a name to be used to identify the services by. Keep the name simple, but informative. We use ‘prod’ as an example:
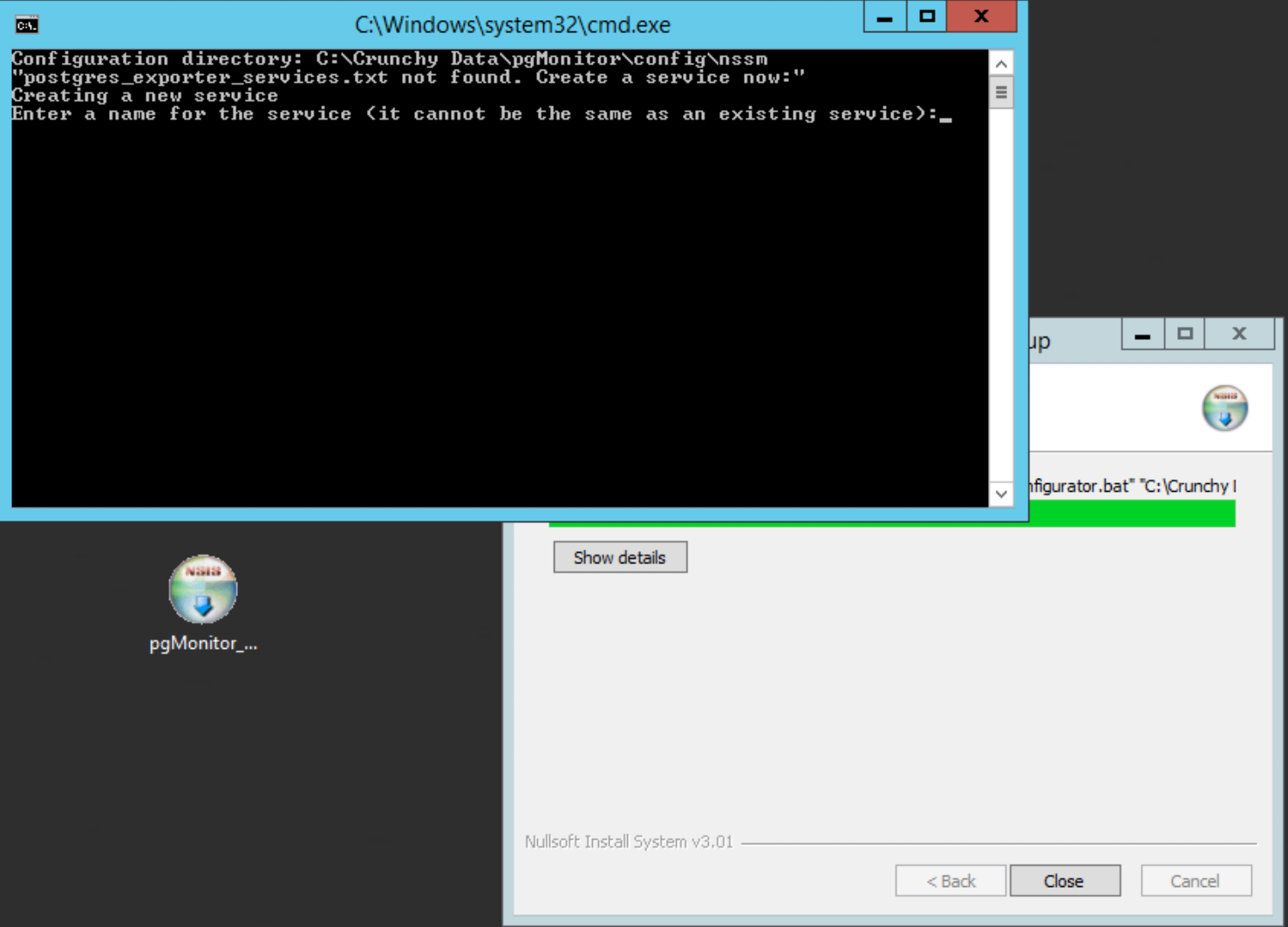
You will then be asked which exporter you’re setting up: the cluster or the per-db. You will need one of each. We start with the global:
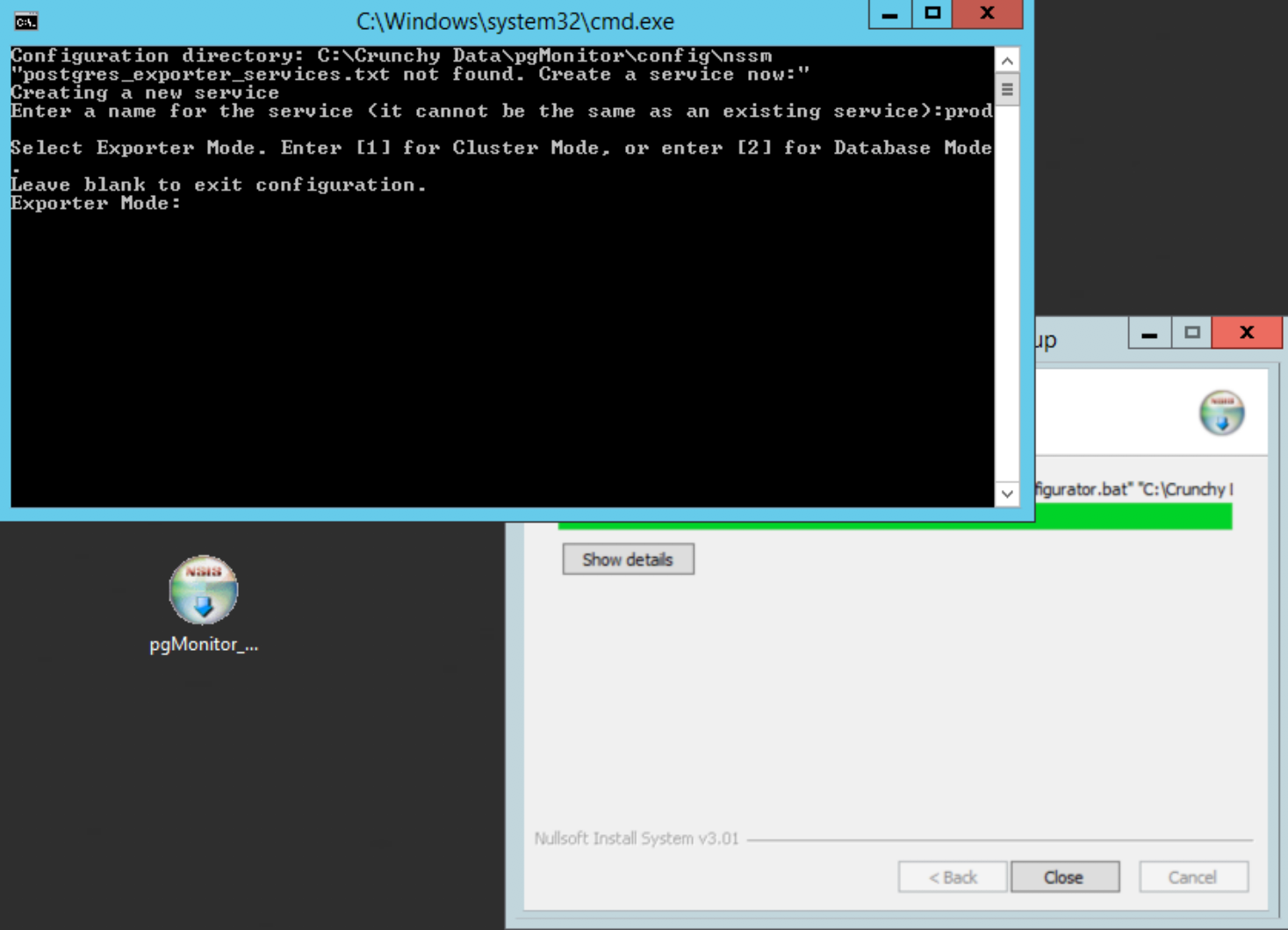
Choose ‘1’ to configure the cluster exporter, then give it a meaningful name, e.g. payroll or whatever the main app is for this PostgreSQL cluster, enter your PostgreSQL version, and specify the default port of 9187:
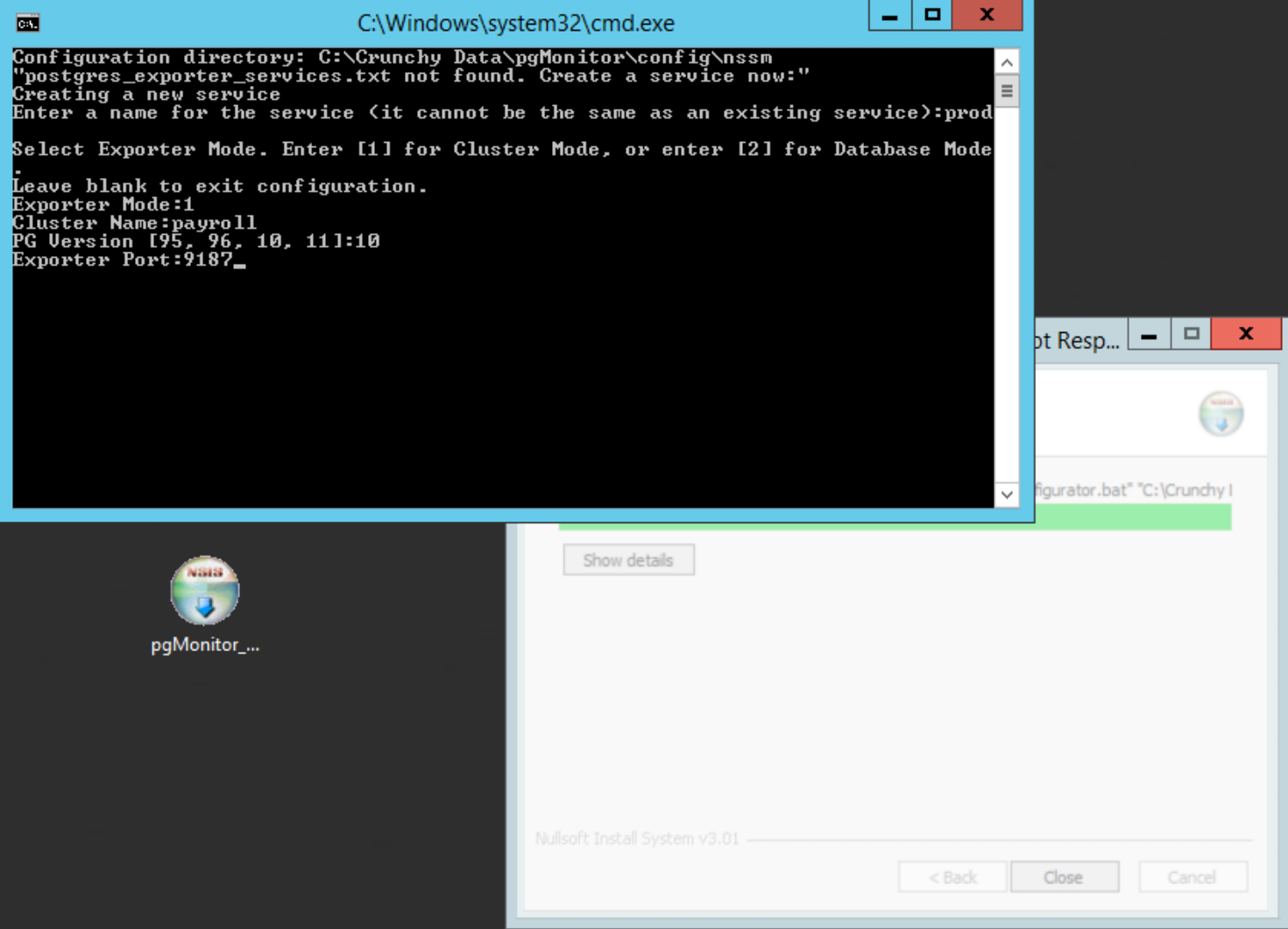
Enter the PostgreSQL connection info. You will need the name of the database superuser account, its password, you can use 127.0.0.1 to connect, and finally enter the port PostgreSQL is listening on:
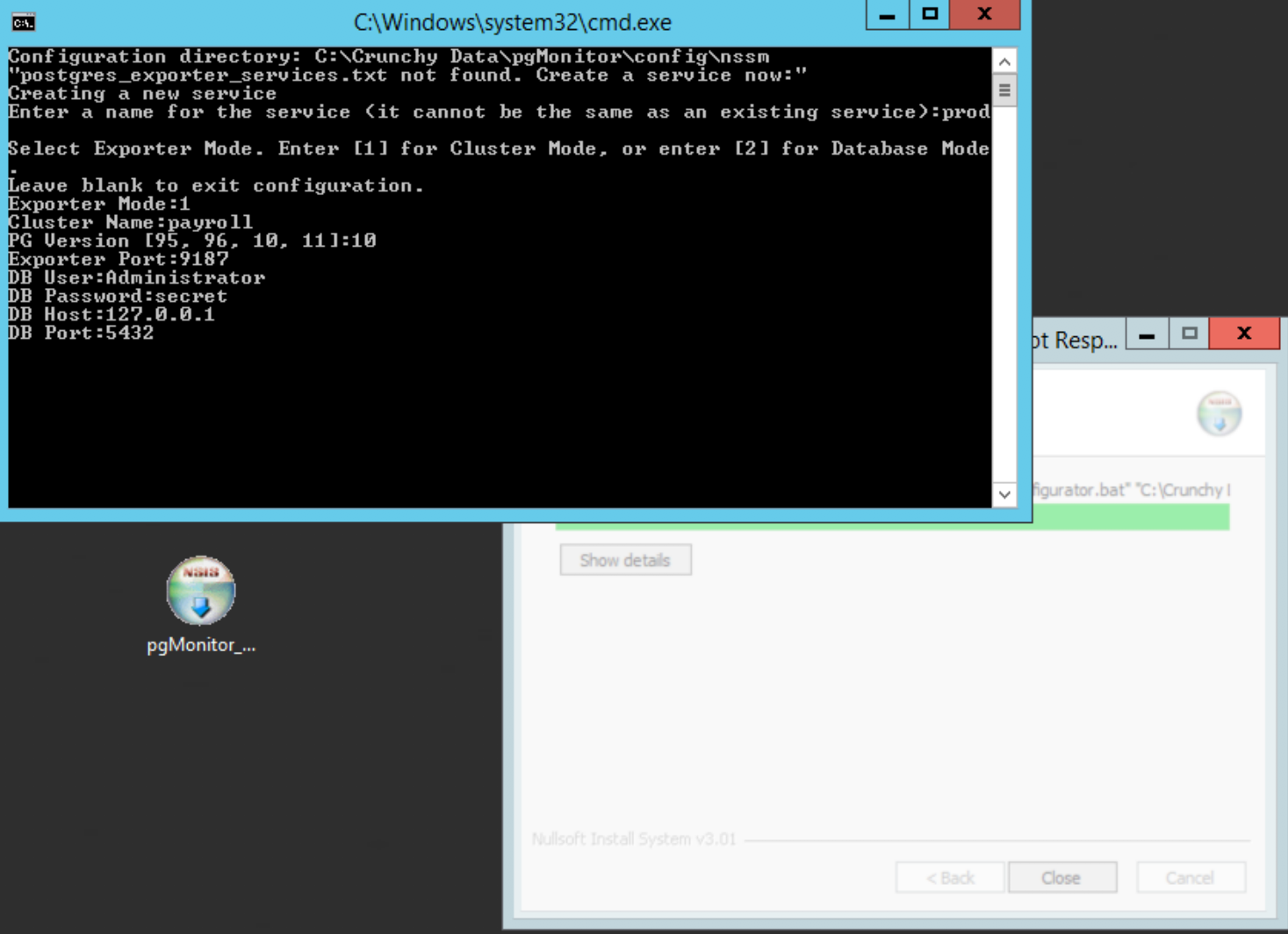
The script will set up the cluster exporter service and bring you back to the main menu. Choose ‘1’ to add a service, name it the same you used in the previous step but append ‘db’ to the name, e.g. payrolldb, and choose ‘2’ for the exporter type:
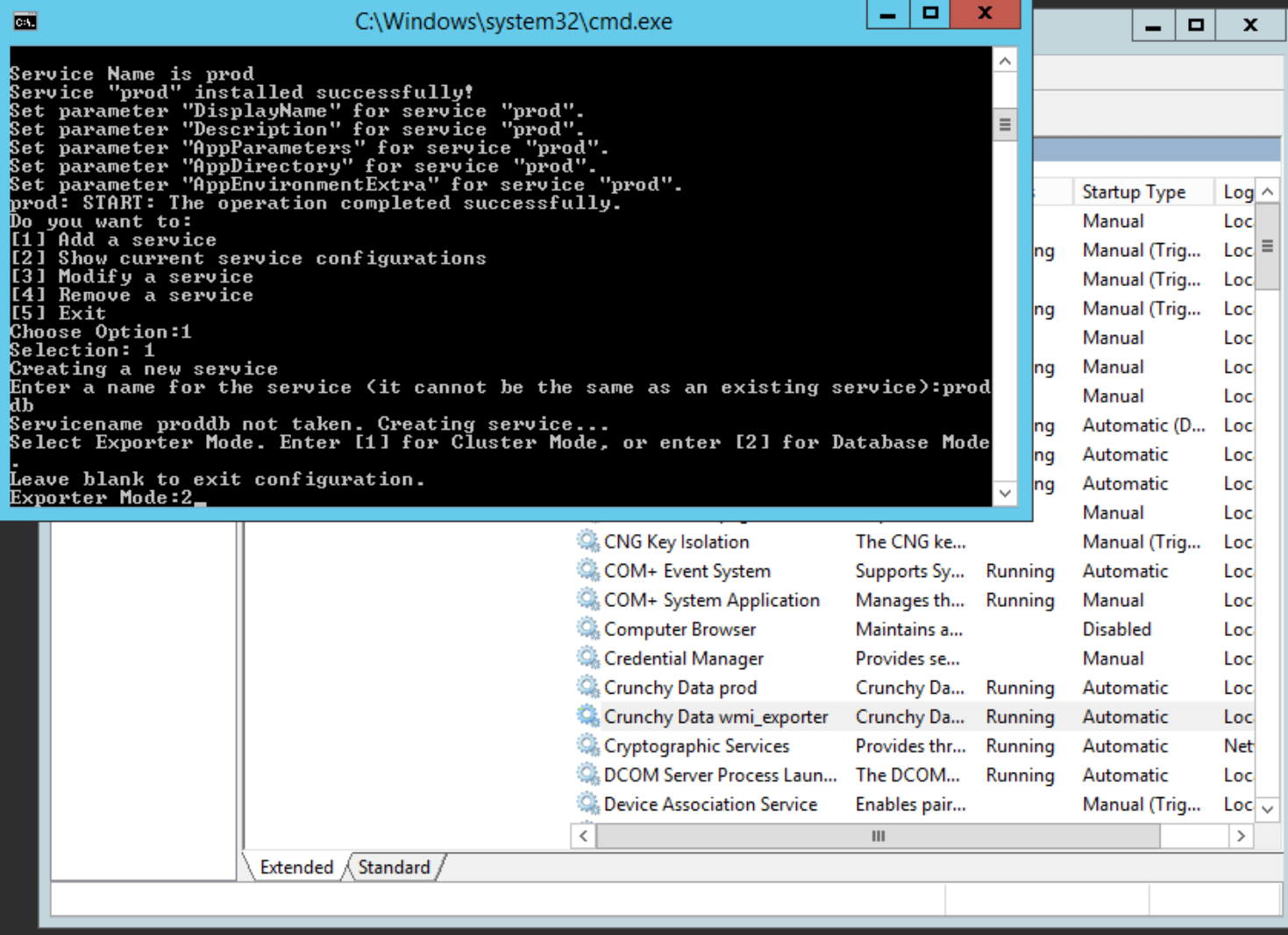
Enter your PostgreSQL version again, then enter ‘9188’ as the port (two exporters cannot share the same port). Enter the same PostgreSQL connection info again. The script will setup the per-db exporter. You may now choose option ‘5’ to exit the script:
Run
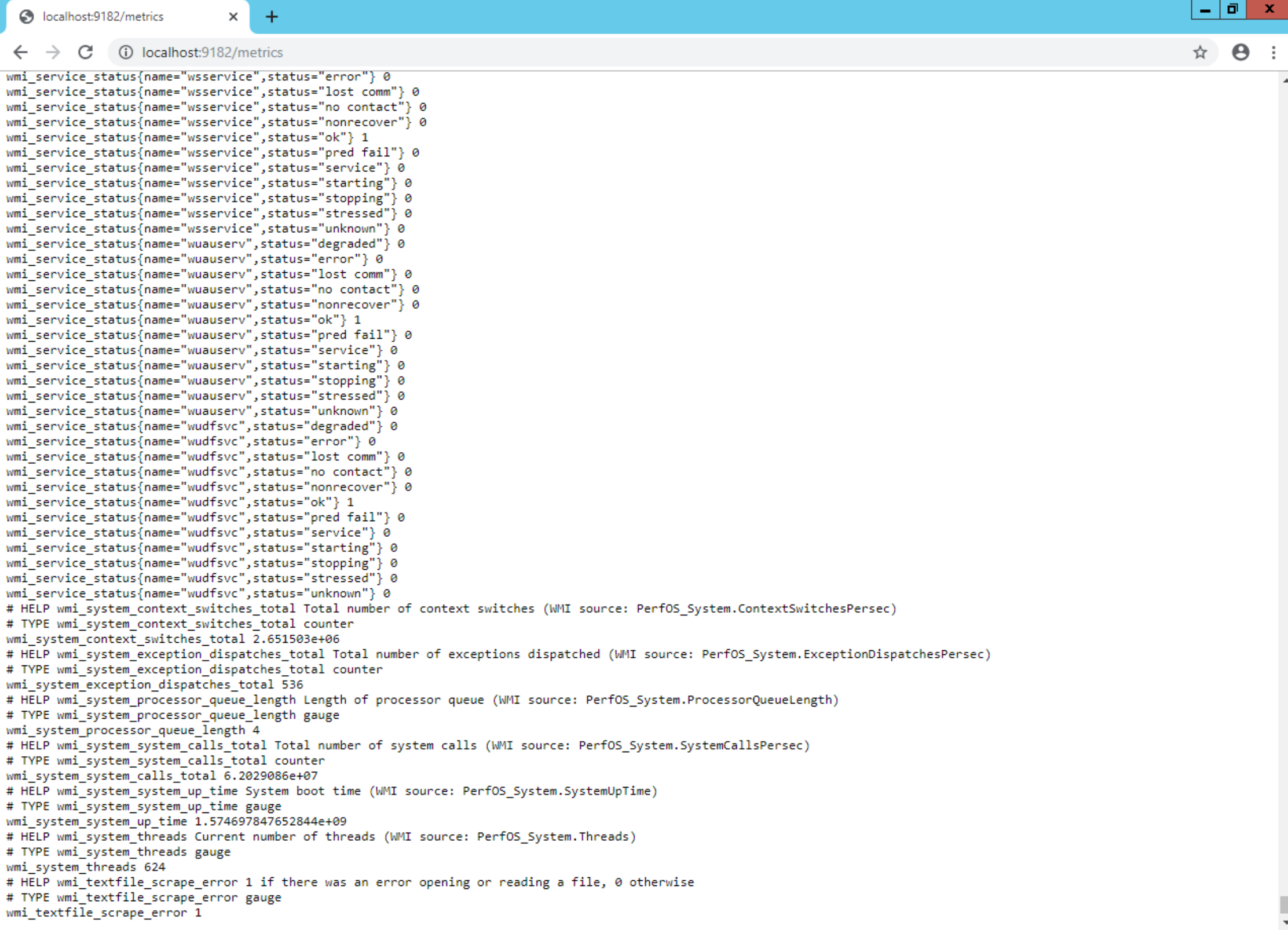
C:\Crunchy Data\pgMonitor\postgres_exporter\##\setup_pg##.sqlagainst yourpostgresdatabase as your PostgreSQL super user replacing##with the major version of your PostgreSQL install (e.g. 96, 10, 11).Confirm that the WMI Exporter is functional by loading http://localhost:9182/metrics in your browser:
Verify the cluster exporter is functional by loading http://localhost:9187/metrics in your browser. You should see multiple metrics that begin with
ccp_: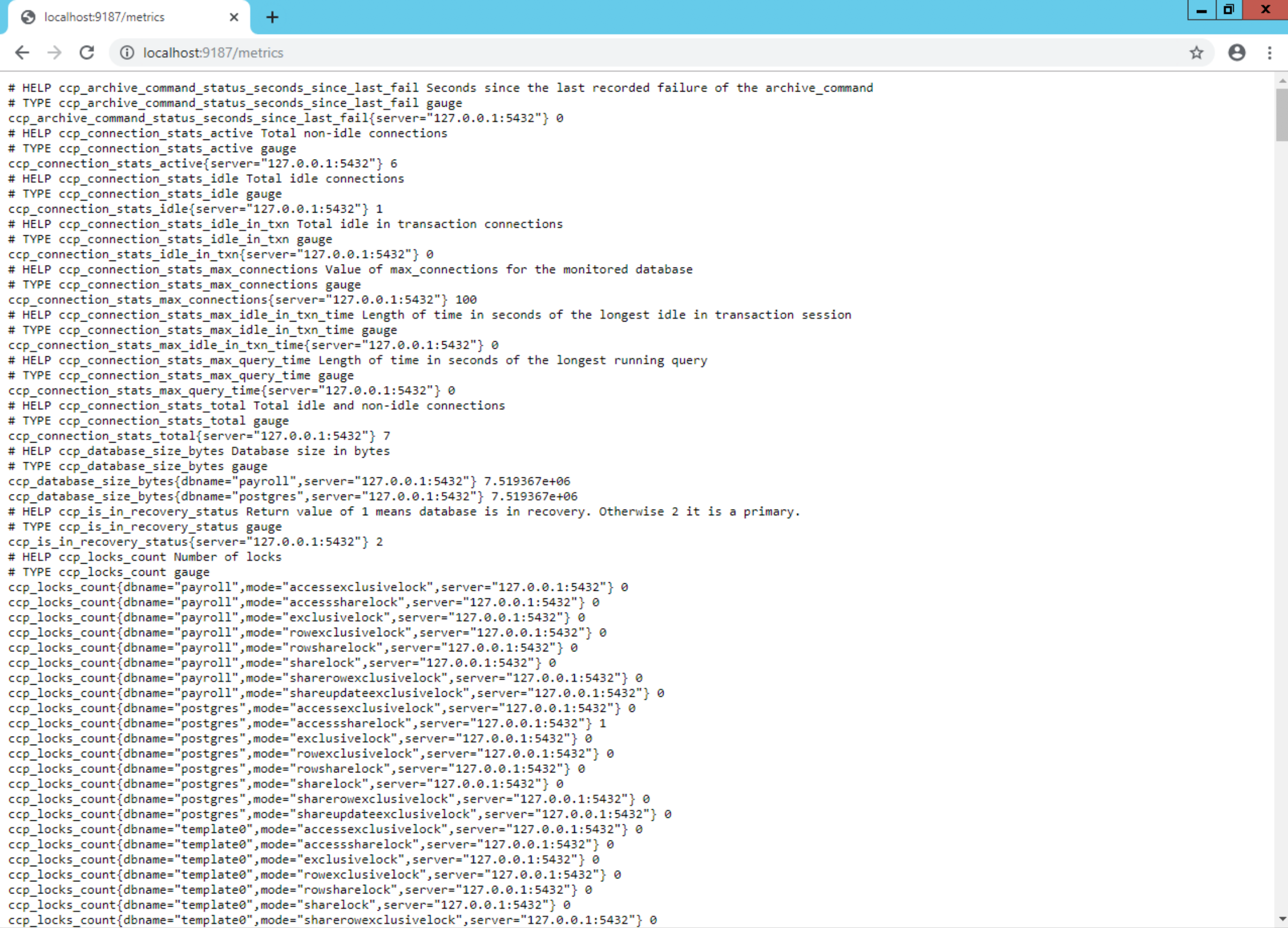
Finally, confirm the per-db eporter is functional by loading http://localhost:9188/metrics in your browser:
Metrics Collected
The metrics collected by our exporters are outlined below.
PostgreSQL
PostgreSQL metrics are collected by the postgres_exporter. pgMonitor uses custom queries for its PG metrics. The default metrics that postgres_exporter comes with are all disabled except for the pg_up metric.
General Metrics
pg_up - Database is up and connectable by metric collector. This is the only metrics that comes with postgres_exporter that is currently used
Common Metrics
Metrics contained in the queries_common.yml file. These metrics are common to all versions of PostgreSQL and are recommended as a minimum default for the global exporter.
ccp_archive_command_status_seconds_since_last_fail - Seconds since the last
archive_commandrun failed. If zero, thearchive_commandis succeeding without error.ccp_database_size_bytes - Total size of each database in PostgreSQL instance
ccp_is_in_recovery_status - Current value of the pg_is_in_recovery() function expressed as 2 for true (instance is a replica) and 1 for false (instance is a primary)
ccp_locks_count - Count of active lock types per database
ccp_pg_settings_checksum_status - Value of checksum monitioring status for pg_catalog.pg_settings (postgresql.conf). 0 = valid config. 1 = settings changed. Settings history is available for review in the table
monitor.pg_settings_checksum. To reset current config to valid after alert, run monitor.pg_settings_checksum_set_valid(). Note this will clear the history table.ccp_postmaster_uptime_seconds - Time interval in seconds since PostgreSQL database was last restarted
ccp_postgresql_version_current - Version of PostgreSQL that this exporter is monitoring. Value is the 6 digit integer returned by the
server_version_numPostgreSQL configuration variable to allow easy monitoring for version changes.ccp_sequence_exhaustion_count - Checks for any sequences that may be close to exhaustion (by default greater than 75% usage). Note this checks the sequences themselves, not the values contained in the columns that use said sequences. Function
monitor.sequence_status()can provide more details if run directly on database instance.ccp_settings_pending_restart_count - Number of settings from pg_settings catalog in a pending_restart state. This value is from the similarly named column found in pg_catalog.pg_settings.
The meaning of the following ccp_transaction_wraparound metrics, and how to manage when they are triggered, is covered more extensively in this blog post: https://info.crunchydata.com/blog/managing-transaction-id-wraparound-in-postgresql
ccp_transaction_wraparound_percent_towards_emergency_autovac - Recommended thresholds set to 75%/95% when first evaluating vacuum settings on new systems. Once those have been reviewed and at least one instance-wide vacuum has been run, recommend thresholds of 110%/125%. Alerting above 100% for extended periods of time means that autovacuum is not able to keep up with current transaction rate and needs further tuning.
ccp_transaction_wraparound_percent_towards_wraparound - Recommend thresholds set to 50%/75%. If any of these thresholds is tripped, current vacuum settings must be evaluated and tuned ASAP. If critical threshold is reached, it is vitally important that vacuum be run on tables with old transaction IDs to avoid the cluster being forced to shut down and only be able to run in single user mode.
The following ccp_stat_bgwriter metrics are statistics collected from the pg_stat_bgwriter view for monitoring performance. These metrics cover important performance information about flushing data out to disk. Please see the documentation for further details on these metrics.
ccp_stat_bgwriter_buffers_alloc
ccp_stat_bgwriter_buffers_backend
ccp_stat_bgwriter_buffers_backend_fsync
ccp_stat_bgwriter_buffers_checkpoint
ccp_stat_bgwriter_buffers_clean
The following ccp_stat_database_* metrics are statistics collected from the pg_stat_database view.
ccp_stat_database_blks_hit
ccp_stat_database_blks_read
ccp_stat_database_conflicts
ccp_stat_database_deadlocks
ccp_stat_database_tup_deleted
ccp_stat_database_tup_fetched
ccp_stat_database_tup_inserted
ccp_stat_database_tup_returned
ccp_stat_database_tup_updated
ccp_stat_database_xact_commit
ccp_stat_database_xact_rollback
PostgreSQL Version Specific Metrics
The following metrics either require special considerations when monitoring specific versions of PostgreSQL, or are only available for specific versions. These metrics are found in the queries_pg##.yml files, where ## is the major version of PG. Unless otherwise noted, the below metrics are available for all versions of PG. These metrics are recommend as a minimum default for the global exporter.
ccp_connection_stats_active - Count of active connections
ccp_connection_stats_idle - Count of idle connections
ccp_connection_stats_idle_in_txn - Count of idle in transaction connections
ccp_connection_stats_max_blocked_query_time - Runtime of longest running query that has been blocked by a heavyweight lock
ccp_connection_stats_max_connections - Current value of max_connections for reference
ccp_connection_stats_max_idle_in_txn_time - Runtime of longest idle in transaction (IIT) session.
ccp_connection_stats_max_query_time - Runtime of longest general query (inclusive of IIT).
ccp_connection_stats_max_blocked_query_time - Runtime of the longest running query that has been blocked by a heavyweight lock
ccp_replication_lag_replay_time - Only provides values on replica instances. Time since replica received and replayed a WAL file. Note this is not the main way to determine if a replica is behind its primary. It only monitors the time the replica replayed the WAL vs what it has received. It is a secondary metric for monitoring WAL replay on the replica itself.
ccp_replication_lag_size_bytes - Only provides values on instances that have attached replicas (primary, cascading replica). Tracks byte lag of every streaming replica connected to this database instance. This is the main way that replication lag is monitored. Note that if you have WAL replay only replicas, this will not be reflected here.
ccp_replication_slots_active - Active state of given replication slot. 1 = true. 0 = false.
ccp_replication_slots_retained_bytes - The amount of WAL (in bytes) being retained for given slot.
ccp_wal_activity_total_size_bytes - Current size in bytes of the WAL directory
ccp_wal_activity_last_5_min_size_bytes - PostgreSQL 10 and later only. Current size in bytes of the last 5 minutes of WAL generation. Includes recycled WALs.
ccp_pg_hba_checksum_status - PostgreSQL 10 and later only. Value of checksum monitioring status for pg_catalog.pg_hba_file_rules (pg_hba.conf). 0 = valid config. 1 = settings changed. Settings history is available for review in the table
monitor.pg_hba_checksum. To reset current config to valid after alert, run monitor.pg_hba_checksum_set_valid(). Note this will clear the history table.ccp_data_checksum_failure_count - PostgreSQL 12 and later only. Total number of checksum failures on this database.
ccp_data_checksum_failure_time_since_last_failure_seconds - PostgreSQL 12 and later only. Time interval in seconds since the last checksum failure was encountered.
Backup Metrics
Backup monitoring only covers pgBackRest at this time. These metrics are found in the queries_backrest.yml file. These metrics only need to be collected once per database instance so should be collected by the global postgres_exporter.
ccp_backrest_last_full_backup_time_since_completion_seconds - Time since completion of last pgBackRest FULL backup
ccp_backrest_last_diff_backup_time_since_completion_seconds - Time since completion of last pgBackRest DIFFERENTIAL backup. Note that FULL backup counts as a successful DIFFERENTIAL for the given stanza.
ccp_backrest_last_incr_backup_time_since_completion_seconds - Time since completion of last pgBackRest INCREMENTAL backup. Note that both FULL and DIFFERENTIAL backups count as a successful INCREMENTAL for the given stanza.
ccp_backrest_last_info_runtime_backup_runtime_seconds - Last successful runtime of each backup type (full/diff/incr).
ccp_backrest_last_info_repo_backup_size_bytes - Actual size of only this individual backup in the pgbackrest repository
ccp_backrest_last_info_repo_total_size_bytes - Total size of this backup in the pgbackrest repository, including all required previous backups and WAL
Per-Database Metrics
These are metrics that are only available on a per-database level. These metrics are found in the queries_per_db.yml file. These metrics are optional and recommended for the non-global, per-db postgres_exporter. They can be included in the global exporter as well if the global database needs per-database metrics monitored. Please note that depending on the number of objects in your database, collecting these metrics can greatly increase the storage requirements for Prometheus since all of these metrics are being collected for each individual object.
- ccp_table_size_size_bytes - Table size inclusive of all indexes in that table
The following ccp_stat_user_tables_* metrics are statistics collected from the pg_stat_user_tables. Please see the PG documentation for descriptions of these metrics.
ccp_stat_user_tables_analyze_count
ccp_stat_user_tables_autoanalyze_count
ccp_stat_user_tables_autovacuum_count
ccp_stat_user_tables_n_tup_del
ccp_stat_user_tables_n_tup_ins
ccp_stat_user_tables_n_tup_upd
ccp_stat_user_tables_vacuum_count
Bloat Metrics
Bloat metrics are only available if the pg_bloat_check script has been setup to run. See instructions above. These metrics are found in the queries_bloat.yml file. These metrics are per-database so, should be used by the per-db postgres_exporter.
ccp_bloat_check_size_bytes - Size of object in bytes
ccp_bloat_check_total_wasted_space_bytes - Total wasted space in bytes of given object
pgBouncer Metrics
The following metric prefixes correspond to the SHOW command views found in the pgBouncer documentation. Each column found in the SHOW view is a separate metric under the respective prefix. Ex: ccp_pgbouncer_pools_client_active corresponds to the SHOW POOLS view’s client_active column. These metrics are found in the queries_bouncer.yml file. These metrics only need to be collected once per database instance so should be collected by the global postgres_exporter.
ccp_pgbouncer_pools - SHOW POOLS
ccp_pgbouncer_databases - SHOW DATABASES
ccp_pgbouncer_clients - SHOW CLIENTS
ccp_pgbouncer_servers - SHOW SERVERS
ccp_pgbouncer_lists - SHOW LISTS
pg_stat_statements Metrics
Collecting all per-query metrics into Prometheus could greatly increase storage requirements and heavily impact performance without sufficient resources. Therefore the metrics below give simplified numeric metrics on overall statistics and Top N queries. N can be set with the PG_STAT_STATEMENTS_LIMIT variable in the exporter sysconfig file (defaults to 20). Note that the statistics for individual queries can only be reset on PG12+. Prior to that, pg_stat_statements must have all statistics reset to redo the top N queries. Due to privileges only available in more recent versions of PostgreSQL, collection of these metrics is only supported in PG10+.
ccp_pg_stat_statements_top_max_time_ms - Maximum time spent in the statement in milliseconds per database/user/query for the top N queries
ccp_pg_stat_statements_top_mean_time_ms - Average query runtime in milliseconds per database/user/query for the top N queries
ccp_pg_stat_statements_top_total_time_ms - Total time spent in the statement in milliseconds per database/user/query for the top N queries
ccp_pg_stat_statements_total_calls_count - Total number of queries run per user/database
ccp_pg_stat_statements_total_mean_time_ms - Mean runtime of all queries per user/database
ccp_pg_stat_statements_total_row_count - Total rows returned from all queries per user/database
ccp_pg_stat_statements_total_time_ms - Total runtime of all queries per user/database
System
*NIX Operating System metrics (Linux, BSD, etc) are collected using the node_exporter provided by the Prometheus team. pgMonitor only collects the default metrics provided by node_exporter, but many additional metrics are available if needed.
Windows Operating System metrics are collected by the wmi_exporter.