Design
Provisioning
So, what does the Postgres Operator actually deploy when you create a cluster?
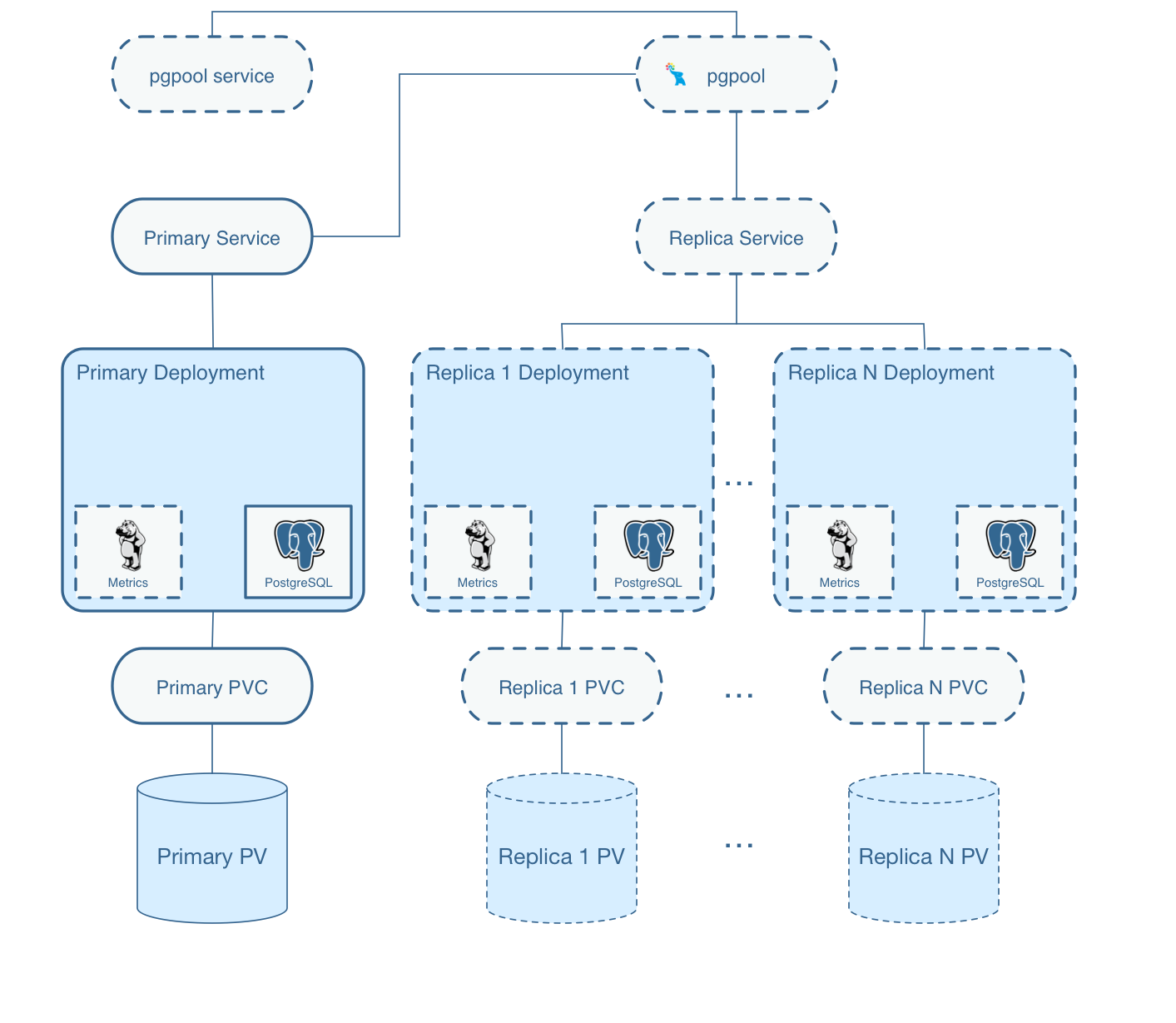
On this diagram, objects with dashed lines are components that are optionally deployed as part of a PostgreSQL Cluster by the operator. Objects with solid lines are the fundamental and required components.
For example, within the Primary Deployment, the metrics container is completely optional. That component can be deployed using either the operator configuration or command line arguments if you want to cause metrics to be collected from the Postgres container.
Replica deployments are similar to the primary deployment but are optional. A replica is not required to be created unless the capability for one is necessary. As you scale up the Postgres cluster, the standard set of components gets deployed and replication to the primary is started.
Notice that each cluster deployment gets its own unique Persistent Volumes. Each volume can use different storage configurations which provides fined grained placement of the database data files.
There is a Service created for the primary Postgres deployment and a Service created for any replica Postgres deployments within a given Postgres cluster. Primary services match Postgres deployments using a label service-name of the following format:
service-name=mycluster
service-name=mycluster-replica
The postgres-operator design incorporates the following concepts:
Custom Resource Definitions
Kubernetes Custom Resource Definitions are used in the design of the PostgreSQL Operator to define the following:
- Cluster - pgclusters
- Backup - pgbackups
- Policy - pgpolicies
- Tasks - pgtasks
Metadata about the PostgreSQL cluster deployments are stored within these CRD resources which act as the source of truth for the PostgreSQL Operator. The Operator makes use of custom resource definitions to maintain state and resource definitions as offered by the Operator.
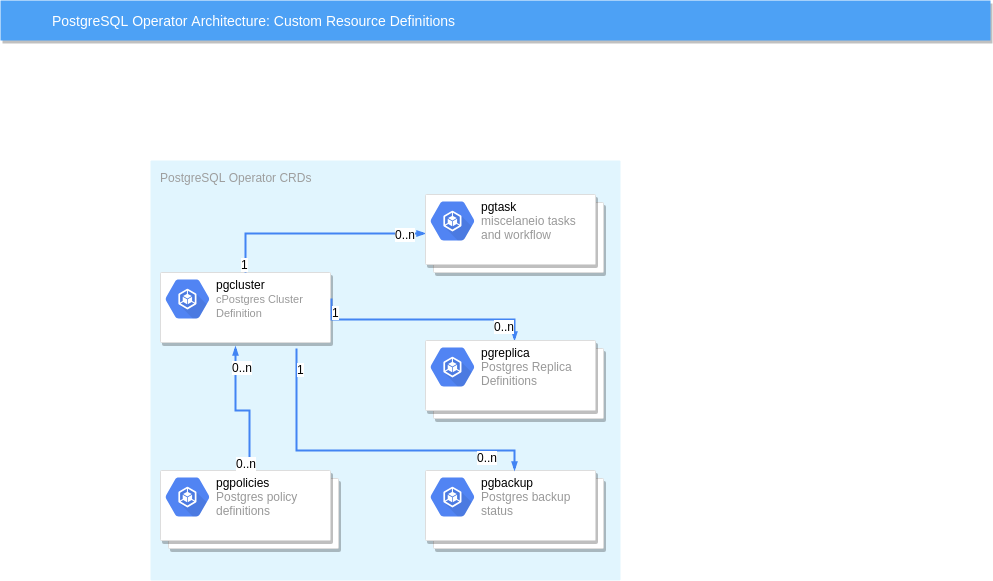
In this above diagram, the CRDs heavily used by the Operator include:
- pgcluster - defines the Postgres cluster definition, new cluster requests are captured in a unique pgcluster resource for that Postgres cluster
- pgtask - workflow and other related administration tasks are captured within a set of pgtasks for a given pgcluster
- pgbackup - when you run a pgbasebackup, a pgbackup is created to hold the workflow and status of the last backup job, this CRD will eventually be deprecated in favor of a more general pgtask resource
- pgreplica - when you create a Postgres replica, a pgreplica CRD is created to define that replica
Security Context Constraints
In an Openshift installation of the PostgreSQL Operator, a custom Security Context Constraint (SCC) is used to customize the control permissions for the pgcluster pods. The PGO SCC adds file system group (fsgroup) 26 to the pod’s existing security context and will be used in place of Openshift’s default restricted SCC.
Event Listeners
Kubernetes events are created for the Operator CRD resources when new resources are made, deleted, or updated. These events are processed by the Operator to perform asynchronous actions.
As events are captured, controller logic is executed within the Operator to perform the bulk of operator logic.
REST API
A feature of the Operator is to provide a REST API upon which users or custom applications can inspect and cause actions within the Operator such as provisioning resources or viewing status of resources.
This API is secured by a RBAC (role based access control) security model whereby each API call has a permission assigned to it. API roles are defined to provide granular authorization to Operator services.
Command Line Interface
One of the unique features of the Operator is the pgo command line interface (CLI). This tool is used by a normal end-user to create databases or clusters, or make changes to existing databases.
The CLI interacts with the REST API deployed within the postgres-operator deployment.
Node Affinity
You can have the Operator add a node affinity section to a new Cluster Deployment if you want to cause Kubernetes to attempt to schedule a primary cluster to a specific Kubernetes node.
You can see the nodes on your Kube cluster by running the following:
kubectl get nodes
You can then specify one of those names (e.g. kubeadm-node2) when creating a cluster;
pgo create cluster thatcluster --node-label=kubeadm-node2
The affinity rule inserted in the Deployment uses a preferred strategy so that if the node were down or not available, Kubernetes will go ahead and schedule the Pod on another node.
When you scale up a Cluster and add a replica, the scaling will
take into account the use of --node-label. If it sees that a
cluster was created with a specific node name, then the replica
Deployment will add an affinity rule to attempt to schedule
Fail-over
Manual and automated fail-over are supported in the Operator within a single Kubernetes cluster.
Manual failover is performed by API actions involving a query and then a target being specified to pick the fail-over replica target.
Automatic fail-over is performed by the Operator by evaluating the readiness of a primary. Automated fail-over can be globally specified for all clusters or specific clusters.
Users can configure the Operator to replace a failed primary with a new replica if they want that behavior.
The fail-over logic includes:
- deletion of the failed primary Deployment
- pick the best replica to become the new primary
- label change of the targeted Replica to match the primary Service
- execute the PostgreSQL promote command on the targeted replica
pgbackrest Integration
The Operator integrates various features of the pgbackrest backup and restore project. A key component added to the Operator is the pgo-backrest-repo container, this container acts as a pgBackRest remote repository for the Postgres cluster to use for storing archive files and backups.
The following diagrams depicts some of the integration features:

In this diagram, starting from left to right we see the following:
a user when they enter pgo backup mycluster –backup-type=pgbackrest will cause a pgo-backrest container to be run as a Job, that container will execute a pgbackrest backup command in the pgBackRest repository container to perform the backup function.
a user when they enter pgo show backup mycluster –backup-type=pgbackrest will cause a pgbackrest info command to be executed on the pgBackRest repository container, the info output is sent directly back to the user to view
the Postgres container itself will use an archive command, pgbackrest archive-push to send archives to the pgBackRest repository container
the user entering pgo create cluster mycluster –pgbackrest will cause a pgBackRest repository container deployment to be created, that repository is exclusively used for this Postgres cluster
lastly, a user entering pgo restore mycluster will cause a pgo-backrest-restore container to be created as a Job, that container executes the pgbackrest restore command
pgbackrest Restore
The pgbackrest restore command is implemented as the pgo restore command. This command is destructive in the sense that it is meant to restore a PG cluster meaning it will revert the PG cluster to a restore point that is kept in the pgbackrest repository. The prior primary data is not deleted but left in a PVC to be manually cleaned up by a DBA. The restored PG cluster will work against a new PVC created from the restore workflow.
When doing a pgo restore, here is the workflow the Operator executes:
- turn off autofail if it is enabled for this PG cluster
- allocate a new PVC to hold the restored PG data
- delete the the current primary database deployment
- update the pgbackrest repo for this PG cluster with a new data path of the new PVC
- create a pgo-backrest-restore job, this job executes the pgbackrest restore command from the pgo-backrest-restore container, this Job mounts the newly created PVC
- once the restore job completes, a new primary Deployment is created which mounts the restored PVC volume
At this point the PG database is back in a working state. DBAs are still responsible to re-enable autofail using pgo update cluster and also perform a pgBackRest backup after the new primary is ready. This version of the Operator also does not handle any errors in the PG replicas after a restore, that is left for the DBA to handle.
Other things to take into account before you do a restore:
- if a schedule has been created for this PG cluster, delete that schedule prior to performing a restore
- If your database has been paused after the target restore was completed, then you would need to run the psql command select pg_wal_replay_resume() to complete the recovery, on PG 9.6⁄9.5 systems, the command you will use is select pg_xlog_replay_resume(). You can confirm the status of your database by using the built in postgres admin functions found here:
- a pgBackRest restore is destructive in the sense that it deletes the existing primary deployment for the cluster prior to creating a new deployment containing the restored primary database. However, in the event that the pgBackRest restore job fails, the
pgo restorecommand be can be run again, and instead of first deleting the primary deployment (since one no longer exists), a new primary will simply be created according to any options specified. Additionally, even though the original primary deployment will be deleted, the original primary PVC will remain. - there is currently no Operator validation of user entered pgBackRest command options, you will need to make sure to enter these correctly, if not the pgBackRest restore command can fail.
- the restore workflow does not perform a backup after the restore nor does it verify that any replicas are in a working status after the restore, it is possible you might have to take actions on the replica to get them back to replicating with the new restored primary.
- pgbackrest.org suggests running a pgbackrest backup after a restore, this needs to be done by the DBA as part of a restore
- when performing a pgBackRest restore, the node-label flag can be utilized to target a specific node for both the pgBackRest restore job and the new (i.e. restored) primary deployment that is then created for the cluster. If a node label is not specified, the restore job will not target any specific node, and the restored primary deployment will inherit any node labels defined for the original primary deployment.
PGO Scheduler
The Operator includes a cronlike scheduler application called pgo-scheduler. Its purpose
is to run automated tasks such as PostgreSQL backups or SQL policies against PostgreSQL clusters
created by the Operator.
PGO Scheduler watches Kubernetes for configmaps with the label crunchy-scheduler=true in the
same namespace the Operator is deployed. The configmaps are json objects that describe the schedule
such as:
- Cron like schedule such as: * * * * *
- Type of task:
pgbackrest,pgbasebackuporpolicy
Schedules are removed automatically when the configmaps are deleted.
PGO Scheduler uses the UTC timezone for all schedules.
Schedule Expression Format
Schedules are expressed using the following rules:
Field name | Mandatory? | Allowed values | Allowed special characters
---------- | ---------- | -------------- | --------------------------
Seconds | Yes | 0-59 | * / , -
Minutes | Yes | 0-59 | * / , -
Hours | Yes | 0-23 | * / , -
Day of month | Yes | 1-31 | * / , - ?
Month | Yes | 1-12 or JAN-DEC | * / , -
Day of week | Yes | 0-6 or SUN-SAT | * / , - ?
pgBackRest Schedules
pgBackRest schedules require pgBackRest enabled on the cluster to backup. The scheduler will not do this on its own.
pgBaseBackup Schedules
pgBaseBackup schedules require a backup PVC to already be created. The operator will make this PVC using the backup commands:
pgo backup mycluster
Policy Schedules
Policy schedules require a SQL policy already created using the Operator. Additionally users can supply both the database in which the policy should run and a secret that contains the username and password of the PostgreSQL role that will run the SQL. If no user is specified the scheduler will default to the replication user provided during cluster creation.