High-Availability
One of the great things about PostgreSQL is its reliability: it is very stable and typically “just works.” However, there are certain things that can happen in the environment that PostgreSQL is deployed in that can affect its uptime, including:
- The database storage disk fails or some other hardware failure occurs
- The network on which the database resides becomes unreachable
- The host operating system becomes unstable and crashes
- A key database file becomes corrupted
- A data center is lost
There may also be downtime events that are due to the normal case of operations, such as performing a minor upgrade, security patching of operating system, hardware upgrade, or other maintenance.
Fortunately, the Crunchy PostgreSQL Operator is prepared for this.
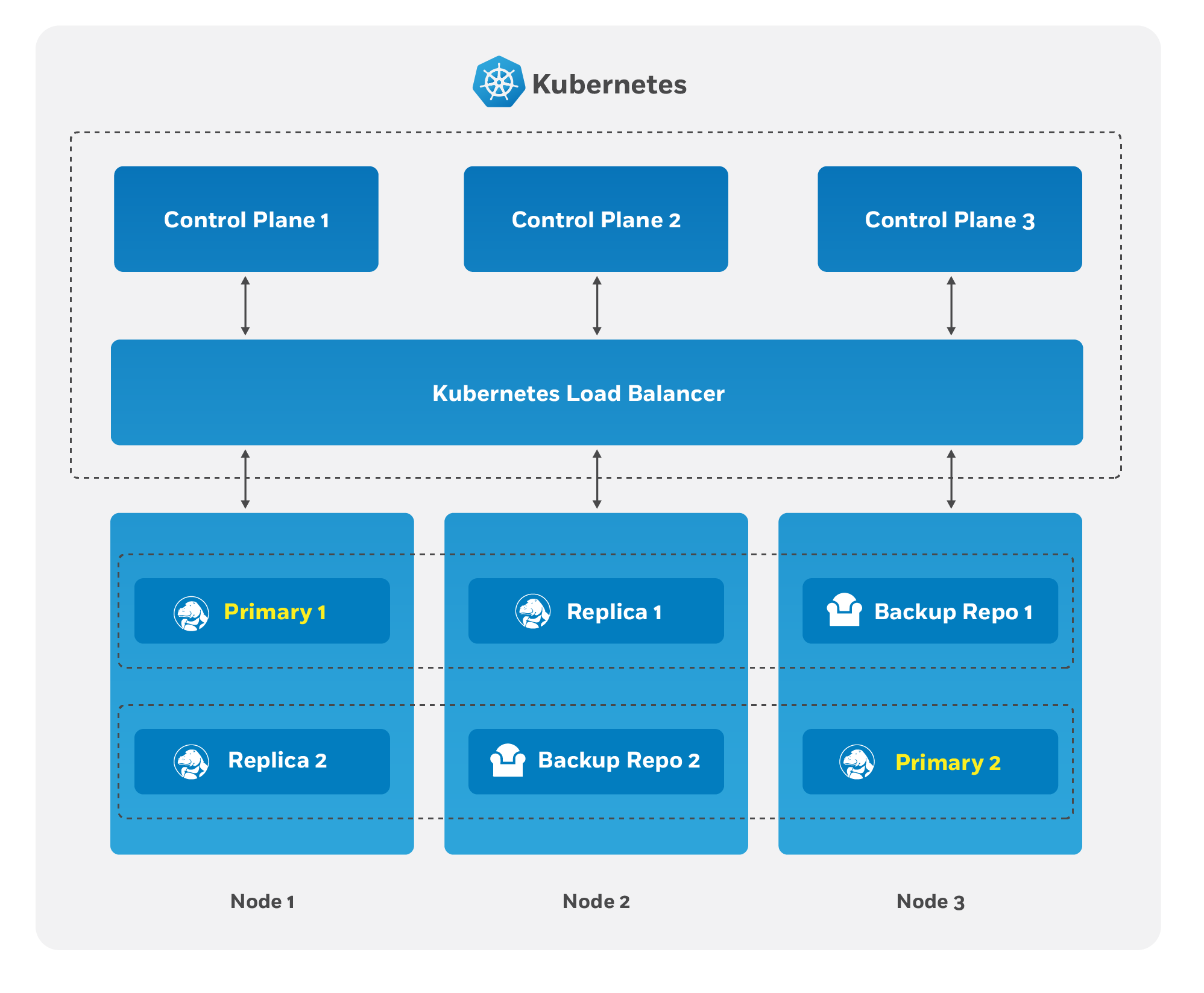
The Crunchy PostgreSQL Operator supports a distributed-consensus based high-availability (HA) system that keeps its managed PostgreSQL clusters up and running, even if the PostgreSQL Operator disappears. Additionally, it leverages Kubernetes specific features such as Pod Anti-Affinity to limit the surface area that could lead to a PostgreSQL cluster becoming unavailable. The PostgreSQL Operator also supports automatic healing of failed primaries and leverages the efficient pgBackRest “delta restore” method, which eliminates the need to fully reprovision a failed cluster!
The Crunchy PostgreSQL Operator also maintains high-availability during a routine task such as a PostgreSQL minor version upgrade.
For workloads that are sensitive to transaction loss, the Crunchy PostgreSQL
Operator supports PostgreSQL synchronous replication, which can be specified
with the --sync-replication when using the pgo create cluster command.
(HA is enabled by default in any newly created PostgreSQL cluster. You can
update this setting by either using the --disable-autofail flag when using
pgo create cluster, or modify the pgo-config ConfigMap [or the pgo.yaml
file] to set DisableAutofail to "true". These can also be set when a
PostgreSQL cluster is running using the pgo update cluster command).
One can also choose to manually failover using the pgo failover command as
well.
The high-availability backing for your PostgreSQL cluster is only as good as your high-availability backing for Kubernetes. To learn more about creating a high-availability Kubernetes cluster, please review the Kubernetes documentation or consult your systems administrator.
The Crunchy PostgreSQL Operator High-Availability Algorithm
A critical aspect of any production-grade PostgreSQL deployment is a reliable and effective high-availability (HA) solution. Organizations want to know that their PostgreSQL deployments can remain available despite various issues that have the potential to disrupt operations, including hardware failures, network outages, software errors, or even human mistakes.
The key portion of high-availability that the PostgreSQL Operator provides is that it delegates the management of HA to the PostgreSQL clusters themselves. This ensures that the PostgreSQL Operator is not a single-point of failure for the availability of any of the PostgreSQL clusters that it manages, as the PostgreSQL Operator is only maintaining the definitions of what should be in the cluster (e.g. how many instances in the cluster, etc.).
Each HA PostgreSQL cluster maintains its availability using concepts that come from the Raft algorithm to achieve distributed consensus. The Raft algorithm (“Reliable, Replicated, Redundant, Fault-Tolerant”) was developed for systems that have one “leader” (i.e. a primary) and one-to-many followers (i.e. replicas) to provide the same fault tolerance and safety as the PAXOS algorithm while being easier to implement.
For the PostgreSQL cluster group to achieve distributed consensus on who the primary (or leader) is, each PostgreSQL cluster leverages the distributed etcd key-value store that is bundled with Kubernetes. After it is elected as the leader, a primary will place a lock in the distributed etcd cluster to indicate that it is the leader. The “lock” serves as the method for the primary to provide a heartbeat: the primary will periodically update the lock with the latest time it was able to access the lock. As long as each replica sees that the lock was updated within the allowable automated failover time, the replicas will continue to follow the leader.
The “log replication” portion that is defined in the Raft algorithm is handled by PostgreSQL in two ways. First, the primary instance will replicate changes to each replica based on the rules set up in the provisioning process. For PostgreSQL clusters that leverage “synchronous replication,” a transaction is not considered complete until all changes from those transactions have been sent to all replicas that are subscribed to the primary.
In the above section, note the key word that the transaction are sent to each replica: the replicas will acknowledge receipt of the transaction, but they may not be immediately replayed. We will address how we handle this further down in this section.
During this process, each replica keeps track of how far along in the recovery process it is using a “log sequence number” (LSN), a built-in PostgreSQL serial representation of how many logs have been replayed on each replica. For the purposes of HA, there are two LSNs that need to be considered: the LSN for the last log received by the replica, and the LSN for the changes replayed for the replica. The LSN for the latest changes received can be compared amongst the replicas to determine which one has replayed the most changes, and an important part of the automated failover process.
The replicas periodically check in on the lock to see if it has been updated by the primary within the allowable automated failover timeout. Each replica checks in at a randomly set interval, which is a key part of Raft algorithm that helps to ensure consensus during an election process. If a replica believes that the primary is unavailable, it becomes a candidate and initiates an election and votes for itself as the new primary. A candidate must receive a majority of votes in a cluster in order to be elected as the new primary.
There are several cases for how the election can occur. If a replica believes that a primary is down and starts an election, but the primary is actually not down, the replica will not receive enough votes to become a new primary and will go back to following and replaying the changes from the primary.
In the case where the primary is down, the first replica to notice this starts an election. Per the Raft algorithm, each available replica compares which one has the latest changes available, based upon the LSN of the latest logs received. The replica with the latest LSN wins and receives the vote of the other replica. The replica with the majority of the votes wins. In the event that two replicas’ logs have the same LSN, the tie goes to the replica that initiated the voting request.
Once an election is decided, the winning replica is immediately promoted to be a primary and takes a new lock in the distributed etcd cluster. If the new primary has not finished replaying all of its transactions logs, it must do so in order to reach the desired state based on the LSN. Once the logs are finished being replayed, the primary is able to accept new queries.
At this point, any existing replicas are updated to follow the new primary.
When the old primary tries to become available again, it realizes that it has been deposed as the leader and must be healed. The old primary determines what kind of replica it should be based upon the CRD, which allows it to set itself up with appropriate attributes. It is then restored from the pgBackRest backup archive using the “delta restore” feature, which heals the instance and makes it ready to follow the new primary, which is known as “auto healing.”
How The Crunchy PostgreSQL Operator Uses Pod Anti-Affinity
By default, when a new PostgreSQL cluster is created using the PostgreSQL Operator, pod anti-affinity rules will be applied to any deployments comprising the full PG cluster (please note that default pod anti-affinity does not apply to any Kubernetes jobs created by the PostgreSQL Operator). This includes:
- The primary PG deployment
- The deployments for each PG replica
- The
pgBackrestdedicated repository deployment - The
pgBouncerdeployment (if enabled for the cluster)
There are three types of Pod Anti-Affinity rules that the Crunchy PostgreSQL Operator supports:
preferred: Kubernetes will try to schedule any pods within a PostgreSQL cluster to different nodes, but in the event it must schedule two pods on the same Node, it will. As described above, this is the default option.required: Kubernetes will schedule pods within a PostgreSQL cluster to different Nodes, but in the event it cannot schedule a pod to a different Node, it will not schedule the pod until a different node is available. While this guarantees that no pod will share the same node, it can also lead to downtime events as well. This uses therequiredDuringSchedulingIgnoredDuringExecutionaffinity rule.disabled: Pod Anti-Affinity is not used.
With the default preferred Pod Anti-Affinity rule enabled, Kubernetes will
attempt to schedule pods created by each of the separate deployments above on a
unique node, but will not guarantee that this will occur. This ensures that the
pods comprising the PostgreSQL cluster can always be scheduled, though perhaps
not always on the desired node. This is specifically done using the following:
- The
preferredDuringSchedulingIgnoredDuringExecutionaffinity type, which defines an anti-affinity rule that Kubernetes will attempt to adhere to, but will not guarantee will occur during Pod scheduling - A combination of labels that uniquely identify the pods created by the various Deployments listed above
- A topology key of
kubernetes.io/hostname, which instructs Kubernetes to schedule a pod on specific Node only if there is not already another pod in the PostgreSQL cluster scheduled on that same Node
If you want to explicitly create a PostgreSQL cluster with the preferred Pod
Anti-Affinity rule, you can execute the pgo create command using the
--pod-anti-affinity flag similar to this:
pgo create cluster hacluster --replica-count=2 --pod-anti-affinity=preferredor it can also be explicitly enabled globally for all clusters by setting
PodAntiAffinity to preferred in the pgo.yaml configuration file.
If you want to create a PostgreSQL cluster with the required Pod Anti-Affinity
rule, you can execute a command similar to this:
pgo create cluster hacluster --replica-count=2 --pod-anti-affinity=requiredor set the required option globally for all clusters by setting
PodAntiAffinity to required in the pgo.yaml configuration file.
When required is utilized for the default pod anti-affinity, a separate node
is required for each deployment listed above comprising the PG cluster. This
ensures that the cluster remains highly-available by ensuring that node failures
do not impact any other deployments in the cluster. However, this does mean that
the PostgreSQL primary, each PostgreSQL replica, the pgBackRest repository and,
if deployed, the pgBouncer Pods will each require a unique node, meaning
the minimum number of Nodes required for the Kubernetes cluster will increase as
more Pods are added to the PostgreSQL cluster. Further, if an insufficient
number of nodes are available to support this configuration, certain deployments
will fail, since it will not be possible for Kubernetes to successfully schedule
the pods for each deployment.
It is possible to fine tune the pod anti-affinity rules further, specifically,
set different affinity rules for the PostgreSQL, pgBackRest, and pgBouncer
Deployments. These can be handled by the following flags on pgo create cluster:
--pod-anti-affinity: Sets the pod anti-affinity rules for all the managed Deployments in the cluster (PostgreSQL, pgBackRest, pgBouncer)--pod-anti-affinity-pgbackrest: Sets the pod anti-affinity rules for only the pgBackRest Deployment. This takes precedence over the value of--pod-anti-affinity.--pod-anti-affinity-pgbouncer: Sets the pod anti-affinity rules for only the pgBouncer Deployment. This takes precedence over the value of--pod-anti-affinity.
For example, to use required pod anti-affinity between PostgreSQL instances
but use only preferred anti-affinity for pgBackRest and pgBouncer, you could
use the following command:
pgo create cluster hippo --replicas=2 --pgbouncer \
--pod-anti-affinity=required \
--pod-anti-affinity=preferred \
--pod-anti-afinity=preferred
Synchronous Replication: Guarding Against Transactions Loss
Clusters managed by the Crunchy PostgreSQL Operator can be deployed with synchronous replication, which is useful for workloads that are sensitive to losing transactions, as PostgreSQL will not consider a transaction to be committed until it is committed to all synchronous replicas connected to a primary. This provides a higher guarantee of data consistency and, when a healthy synchronous replica is present, a guarantee of the most up-to-date data during a failover event.
This comes at a cost of performance: PostgreSQL has to wait for a transaction to be committed on all synchronous replicas, and a connected client will have to wait longer than if the transaction only had to be committed on the primary (which is how asynchronous replication works). Additionally, there is a potential impact to availability: if a synchronous replica crashes, any writes to the primary will be blocked until a replica is promoted to become a new synchronous replica of the primary.
You can enable synchronous replication by using the --sync-replication flag
with the pgo create command, e.g.:
pgo create cluster hacluster --replica-count=2 --sync-replicationNode Affinity
Kubernetes Node Affinity can be used to scheduled Pods to specific Nodes within a Kubernetes cluster. This can be useful when you want your PostgreSQL instances to take advantage of specific hardware (e.g. for geospatial applications) or if you want to have a replica instance deployed to a specific region within your Kubernetes cluster for high-availability purposes.
The PostgreSQL Operator provides users with the ability to apply Node Affinity
rules using the --node-label flag on the pgo create and the pgo scale
commands. Node Affinity directs Kubernetes to attempt to schedule these
PostgreSQL instances to the specified Node label.
To get a list of available Node labels:
kubectl get nodes --show-labels
You can then specify one of those Kubernetes node names (e.g. region=us-east-1)
when creating a PostgreSQL cluster;
pgo create cluster thatcluster --node-label=region=us-east-1
By default, node affinity uses the preferred scheduling strategy (similar to
what is described in the [Pod Anti-Affinity](“#how-the-crunchy-postgresql-operator-uses-pod-anti-affinity”)
section above), so if a Pod cannot be scheduled to a particular Node matching
the label, it will be scheduled to a different Node.
The PostgreSQL Operator supports two different types of node affinity:
preferredrequired
which can be selected with the --node-affinity-type flag, e.g:
pgo create cluster hippo \
--node-label=region=us-east-1 --node-affinity-type=required
When creating a cluster, the node affinity rules will be applied to the primary
and any other PostgreSQL instances that are added. If you would like to specify
a node affinity rule for a specific instance, you can do so with the
pgo scale command and the
--node-label and --node-affinity-type flags, i.e:
pgo scale cluster hippo \
--node-label=region=us-south-1 --node-affinity-type=required
Tolerations
Kubernetes Tolerations can help with the scheduling of Pods to appropriate nodes. There are many reasons that a Kubernetes administrator may want to use tolerations, such as restricting the types of Pods that can be assigned to particular Nodes. Reasoning and strategy for using taints and tolerations is outside the scope of this documentation.
The PostgreSQL Operator supports the setting of tolerations across all
PostgreSQL instances in a cluster, as well as for each particular PostgreSQL
instance within a cluster. Both the pgo create cluster
and pgo scale commands
support the --toleration flag, which allows for one or more tolerations to be
added to a PostgreSQL cluster. Values accepted by the --toleration use the
following format:
rule:Effect
where a rule can represent existence (e.g. key) or equality (key=value)
and Effect is one of NoSchedule, PreferNoSchedule, or NoExecute. For
more information on how tolerations work, please refer to the
Kubernetes documentation.
For example, to add two tolerations to a new PostgreSQL cluster, one that is an
existence toleration for a key of ssd and the other that is an equality
toleration for a key/value pair of zone/east, you can run the following
command:
pgo create cluster hippo \
--toleration=ssd:NoSchedule \
--toleration=zone=east:NoSchedule
For another example, to assign equality toleration for a key/value pair of
zone/west to a new instance in the hippo cluster, you can run the
following command:
pgo scale hippo --toleration=zone=west:NoSchedule
Tolerations can be updated on an existing cluster. You can do this by either
modifying the pgclusters.crunchydata.com and pgreplicas.crunchydata.com
custom resources directly, e.g. via the kubectl edit command, or with the
pgo update cluster
command. Using the pgo update cluster command, a toleration can be removed by
adding a - at the end of the toleration effect.
For example, to add a toleration of zone=west:NoSchedule and remove the
toleration of zone=east:NoSchedule, you could run the following command:
pgo update cluster hippo \
--toleration=zone=west:NoSchedule \
--toleration=zone-east:NoSchedule-
Once the updates are applied, the PostgreSQL Operator will roll out the changes to the appropriate instances.
Rolling Updates
During the lifecycle of a PostgreSQL cluster, there are certain events that may
require a planned restart, such as an update to a “restart required” PostgreSQL
configuration setting (e.g. shared_buffers)
or a change to a Kubernetes Deployment template (e.g. changing the memory request). Restarts can be disruptive in a high availability deployment, which is
why many setups employ a “rolling update” strategy
(aka a “rolling restart”) to minimize or eliminate downtime during a planned
restart.
Because PostgreSQL is a stateful application, a simple rolling restart strategy will not work: PostgreSQL needs to ensure that there is a primary available that can accept reads and writes. This requires following a method that will minimize the amount of downtime when the primary is taken offline for a restart.
The PostgreSQL Operator provides a mechanism for rolling updates implicitly on
certain operations that change the Deployment templates (e.g. memory updates,
CPU updates, adding tablespaces, modifiny annotations) and explicitly through
the pgo restart
command with the --rolling flag. The PostgreSQL Operator uses the following
algorithm to perform the rolling restart to minimize any potential
interruptions:
Each replica is updated in sequential order. This follows the following process:
The replica is explicitly shut down to ensure any outstanding changes are flushed to disk.
If requested, the PostgreSQL Operator will apply any changes to the Deployment.
The replica is brought back online. The PostgreSQL Operator waits for the replica to become available before it proceeds to the next replica.
The above steps are repeated until all of the replicas are restarted.
A controlled switchover is performed. The PostgreSQL Operator determines which replica is the best candidate to become the new primary. It then demotes the primary to become a replica and promotes the best candidate to become the new primary.
The former primary follows a process similar to what is described in step 1.
The downtime is thus constrained to the amount of time the switchover takes.
A rolling update strategy will be used if any of the following changes are made
to a PostgreSQL cluster, either through the pgo update command or from a
modification to the custom resource:
- Memory resource adjustments
- CPU resource adjustments
- PVC resizes
- Custom annotation changes
- Enabling/disabling the monitoring sidecar on a PostgreSQL cluster (
--metrics) - Enabling/disabling the pgBadger sidecar on a PostgreSQL cluster (
--pgbadger) - S3 bucket name updates
- Tablespace additions
- Toleration modifications