Disaster Recovery
Advanced high-availability and disaster recovery strategies involve spreading your database clusters across multiple data centers to help maximize uptime. In Kubernetes, this technique is known as “federation”. Federated Kubernetes clusters can communicate with each other, coordinate changes, and provide resiliency for applications that have high uptime requirements.
As of this writing, federation in Kubernetes is still in ongoing development and is something we monitor with intense interest. As Kubernetes federation continues to mature, we wanted to provide a way to deploy PostgreSQL clusters managed by the PostgreSQL Operator that can span multiple Kubernetes clusters.
At a high-level, the PostgreSQL Operator follows the “active-standby” data center deployment model for managing the PostgreSQL clusters across Kubernetes clusters. In one Kubernetes cluster, the PostgreSQL Operator deploys PostgreSQL as an “active” PostgreSQL cluster, which means it has one primary and one-or-more replicas. In another Kubernetes cluster, the PostgreSQL cluster is deployed as a “standby” cluster: every PostgreSQL instance is a replica.
A side-effect of this is that in each of the Kubernetes clusters, the PostgreSQL Operator can be used to deploy both active and standby PostgreSQL clusters, allowing you to mix and match! While the mixing and matching may not be ideal for how you deploy your PostgreSQL clusters, it does allow you to perform online moves of your PostgreSQL data to different Kubernetes clusters as well as manual online upgrades.
Lastly, while this feature does extend high-availability, promoting a standby cluster to an active cluster is not automatic. While the PostgreSQL clusters within a Kubernetes cluster support self-managed high-availability, a cross-cluster deployment requires someone to promote the cluster from standby to active.
Standby Cluster Overview
Standby PostgreSQL clusters are managed like any other PostgreSQL cluster that the PostgreSQL Operator manages. For example, adding replicas to a standby cluster is identical to adding them to a primary cluster.
The main difference between a primary and standby cluster is that there is no primary instance on the standby: one PostgreSQL instance is reading in the database changes from either the backup repository or via streaming replication, while other instances are replicas of it.
Any replicas created in the standby cluster are known as cascading replicas, i.e., replicas replicating from a database server that itself is replicating from another database server. More information about cascading replication can be found in the PostgreSQL documentation.
Because standby clusters are effectively read-only, certain functionality that involves making changes to a database, e.g., PostgreSQL user changes, is blocked while a cluster is in standby mode. Additionally, backups and restores are blocked as well. While pgBackRest supports backups from standbys, this requires direct access to the primary database, which cannot be done until the PostgreSQL Operator supports Kubernetes federation.
Types of Standby Clusters
There are three ways to deploy a standby cluster with the Postgres Operator.
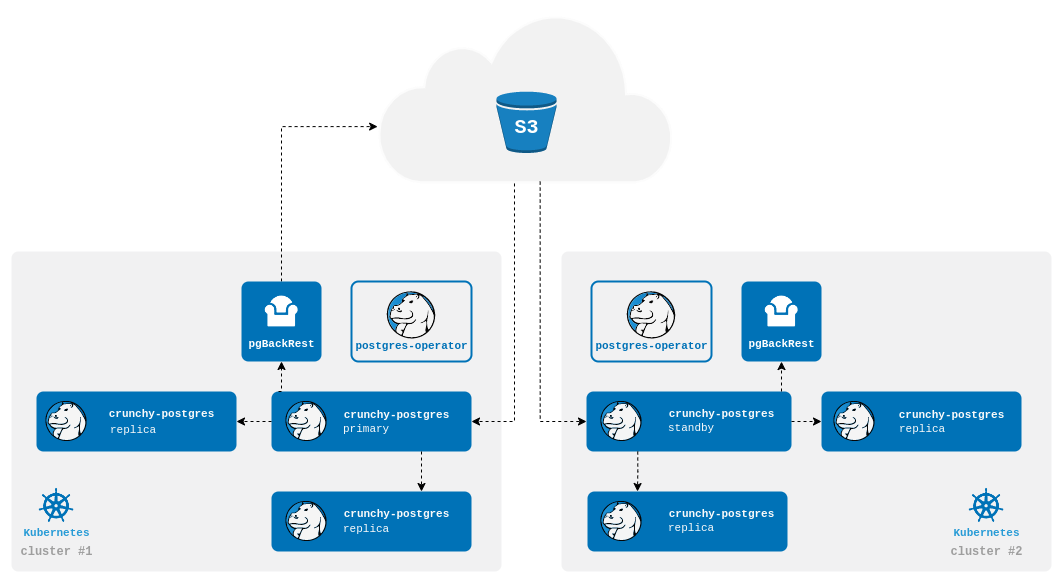
Repo-based Standby
A repo-based standby will connect to a pgBackRest repo stored in an external storage system (S3, GCS, Azure Blob Storage, or any other Kubernetes storage system that can span multiple clusters). The standby cluster will receive WAL files from the repo and will apply those to the database.
Streaming Standby
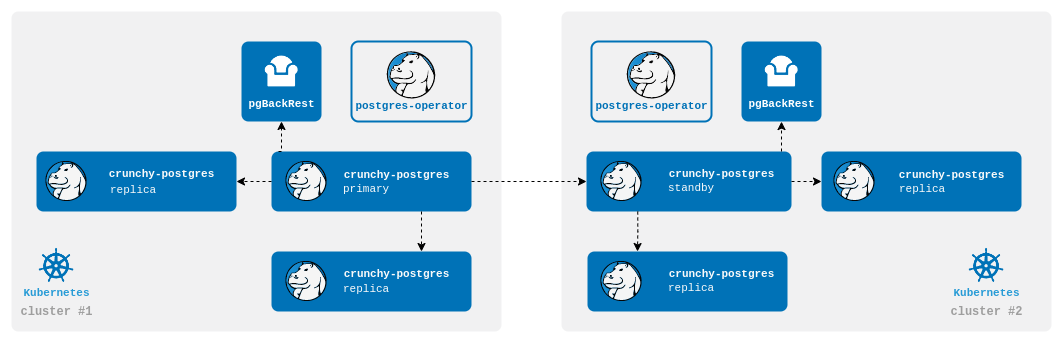
A streaming standby relies on an authenticated connection to the primary over the network. The standby will receive WAL records directly from the primary as they are generated.
Streaming Standby with an External Repo
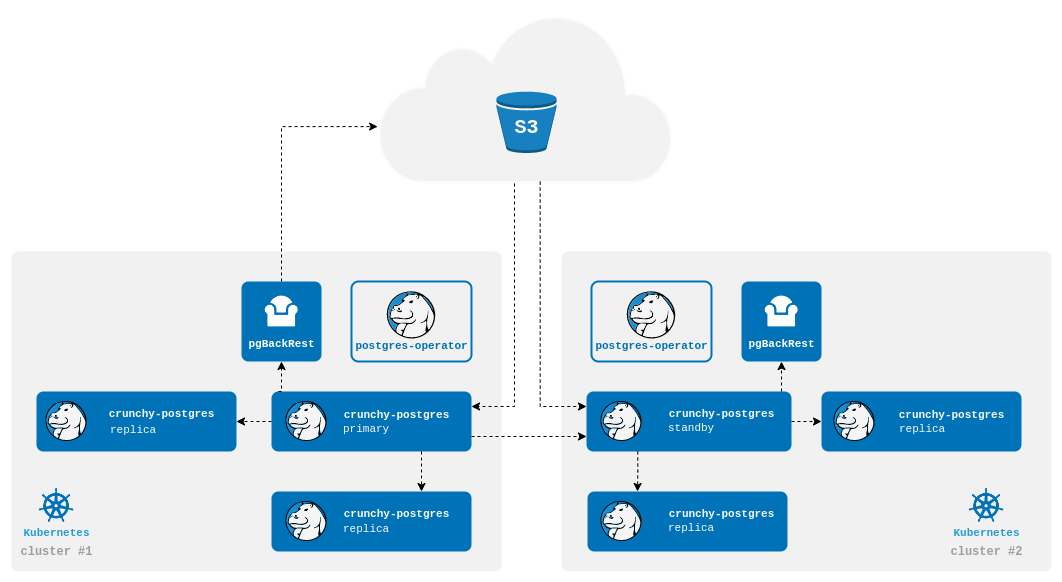
You can also configure the operator to create a cluster that takes advantage of both methods. The standby cluster will bootstrap from the pgBackRest repo and continue to receive WAL files as they are pushed to the repo. The cluster will also directly connect to primary and receive WAL records as they are generated. Using a repo while also streaming ensures that your cluster will still be up to date with the pgBackRest repo if streaming falls behind.
For creating a standby Postgres cluster with PGO, please see the disaster recovery tutorial
Promoting a Standby Cluster
There comes a time when a standby cluster needs to be promoted to an active cluster. Promoting a standby cluster means that the standby leader PostgreSQL instance will become a primary and start accepting both reads and writes. This has the net effect of pushing WAL (transaction archives) to the pgBackRest repository. Before doing this, we need to ensure we don’t accidentally create a split-brain scenario.
If you are promoting the standby while the primary is still running, i.e., if this is not a disaster scenario, you will want to shutdown the active PostgreSQL cluster.
The standby can be promoted once the primary is inactive, e.g., is either shutdown or failing.
This process essentially removes the standby configuration from the Kubernetes cluster’s DCS, which
triggers the promotion of the current standby leader to a primary PostgreSQL instance. You can view
this promotion in the PostgreSQL standby leader’s (soon to be active leader’s) logs.
Once the former standby cluster has been successfully promoted to an active PostgreSQL cluster, the original active PostgreSQL cluster can be safely deleted and recreated as a standby cluster.