High Availability
One of the great things about PostgreSQL is its reliability: it is very stable and typically “just works.” However, there are certain things that can happen in the environment that PostgreSQL is deployed in that can affect its uptime, including:
- The database storage disk fails or some other hardware failure occurs
- The network on which the database resides becomes unreachable
- The host operating system becomes unstable and crashes
- A key database file becomes corrupted
- A data center is lost
There may also be downtime events that are due to the normal case of operations, such as performing a minor upgrade, security patching of operating system, hardware upgrade, or other maintenance.
Fortunately, PGO, the Postgres Operator from Crunchy Data, is prepared for this.
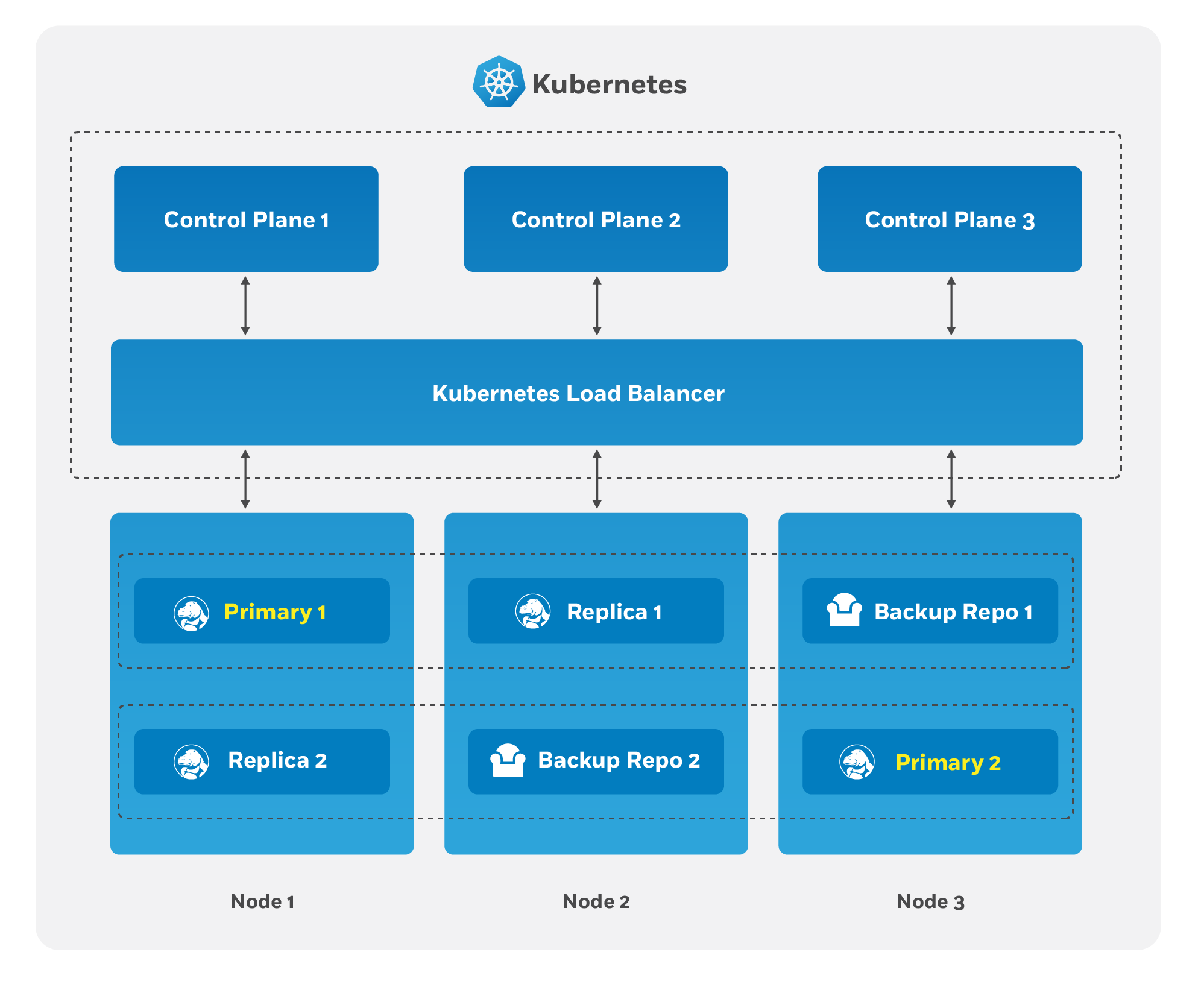
The Crunchy PostgreSQL Operator supports a distributed-consensus based high availability (HA) system that keeps its managed PostgreSQL clusters up and running, even if the PostgreSQL Operator disappears. Additionally, it leverages Kubernetes specific features such as Pod Anti-Affinity to limit the surface area that could lead to a PostgreSQL cluster becoming unavailable. The PostgreSQL Operator also supports automatic healing of failed primaries and leverages the efficient pgBackRest “delta restore” method, which eliminates the need to fully reprovision a failed cluster!
The Crunchy PostgreSQL Operator also maintains high availability during a routine task such as a PostgreSQL minor version upgrade.
For workloads that are sensitive to transaction loss, PGO supports PostgreSQL synchronous replication.
The high availability backing for your PostgreSQL cluster is only as good as your high availability backing for Kubernetes. To learn more about creating a high availability Kubernetes cluster, please review the Kubernetes documentation or consult your systems administrator.
The Crunchy Postgres Operator High Availability Algorithm
A critical aspect of any production-grade PostgreSQL deployment is a reliable and effective high availability (HA) solution. Organizations want to know that their PostgreSQL deployments can remain available despite various issues that have the potential to disrupt operations, including hardware failures, network outages, software errors, or even human mistakes.
The key portion of high availability that the PostgreSQL Operator provides is that it delegates the management of HA to the PostgreSQL clusters themselves. This ensures that the PostgreSQL Operator is not a single-point of failure for the availability of any of the PostgreSQL clusters that it manages, as the PostgreSQL Operator is only maintaining the definitions of what should be in the cluster (e.g. how many instances in the cluster, etc.).
Each HA PostgreSQL cluster maintains its availability by using Patroni to manage
failover when the primary becomes compromised. Patroni stores the primary’s ID in
annotations on a Kubernetes Endpoints object which acts as a lease. The primary
must periodically renew the lease to signal that it’s healthy. If the primary
misses its deadline, replicas compare their WAL positions to see who has the most
up-to-date data. Instances with the latest data try to overwrite the ID on the lease.
The first to succeed becomes the new primary, and all others follow the new primary.
How The Crunchy PostgreSQL Operator Uses Pod Anti-Affinity
Kubernetes has two types of Pod anti-affinity:
- Preferred: With preferred (
preferredDuringSchedulingIgnoredDuringExecution) Pod anti-affinity, Kubernetes will make a best effort to schedule Pods matching the anti-affinity rules to different Nodes. However, if it is not possible to do so, then Kubernetes may schedule one or more Pods to the same Node. - Required: With required (
requiredDuringSchedulingIgnoredDuringExecution) Pod anti-affinity, Kubernetes mandates that each Pod matching the anti-affinity rules must be scheduled to different Nodes. However, a Pod may not be scheduled if Kubernetes cannot find a Node that does not contain a Pod matching the rules.
There is a tradeoff with these two types of pod anti-affinity: while “required” anti-affinity will ensure that all the matching Pods are scheduled on different Nodes, if Kubernetes cannot find an available Node, your Postgres instance may not be scheduled. Likewise, while “preferred” anti-affinity will make a best effort to scheduled your Pods on different Nodes, Kubernetes may compromise and schedule more than one Postgres instance of the same cluster on the same Node.
By understanding these tradeoffs, the makeup of your Kubernetes cluster, and your requirements, you can choose the method that makes the most sense for your Postgres deployment. We’ll show examples of both methods below!
For an example for how pod anti-affinity works with PGO, please see the high availability tutorial.
Synchronous Replication: Guarding Against Transactions Loss
Clusters managed by the Crunchy PostgreSQL Operator can be deployed with synchronous replication, which is useful for workloads that are sensitive to losing transactions, as PostgreSQL will not consider a transaction to be committed until it is committed to all synchronous replicas connected to a primary. This provides a higher guarantee of data consistency and, when a healthy synchronous replica is present, a guarantee of the most up-to-date data during a failover event.
This comes at a cost of performance: PostgreSQL has to wait for a transaction to be committed on all synchronous replicas, and a connected client will have to wait longer than if the transaction only had to be committed on the primary (which is how asynchronous replication works). Additionally, there is a potential impact to availability: if a synchronous replica crashes, any writes to the primary will be blocked until a replica is promoted to become a new synchronous replica of the primary.
Node Affinity
Kubernetes Node Affinity can be used to scheduled Pods to specific Nodes within a Kubernetes cluster. This can be useful when you want your PostgreSQL instances to take advantage of specific hardware (e.g. for geospatial applications) or if you want to have a replica instance deployed to a specific region within your Kubernetes cluster for high availability purposes.
For an example for how node affinity works with PGO, please see the high availability tutorial.
Tolerations
Kubernetes Tolerations can help with the scheduling of Pods to appropriate nodes. There are many reasons that a Kubernetes administrator may want to use tolerations, such as restricting the types of Pods that can be assigned to particular Nodes. Reasoning and strategy for using taints and tolerations is outside the scope of this documentation.
You can configure the tolerations for your Postgres instances on the postgresclusters custom resource.
Pod Topology Spread Constraints
Kubernetes Pod Topology Spread Constraints can also help you efficiently schedule your workloads by ensuring your Pods are not scheduled in only one portion of your Kubernetes cluster. By spreading your Pods across your Kubernetes cluster among your various failure-domains, such as regions, zones, nodes, and other user-defined topology domains, you can achieve high availability as well as efficient resource utilization.
For an example of how pod topology spread constraints work with PGO, please see the high availability tutorial.
Rolling Updates
During the lifecycle of a PostgreSQL cluster, there are certain events that may
require a planned restart, such as an update to a “restart required” PostgreSQL
configuration setting (e.g. shared_buffers)
or a change to a Kubernetes Pod template (e.g. changing the memory request).
Restarts can be disruptive in a high availability deployment, which is
why many setups employ a “rolling update” strategy
(aka a “rolling restart”) to minimize or eliminate downtime during a planned
restart.
Because PostgreSQL is a stateful application, a simple rolling restart strategy will not work: PostgreSQL needs to ensure that there is a primary available that can accept reads and writes. This requires following a method that will minimize the amount of downtime when the primary is taken offline for a restart.
The PostgreSQL Operator uses the following algorithm to perform the rolling restart to minimize any potential interruptions:
Each replica is updated in sequential order. This follows the following process:
The replica is explicitly shut down to ensure any outstanding changes are flushed to disk.
If requested, the PostgreSQL Operator will apply any changes to the Pod.
The replica is brought back online. The PostgreSQL Operator waits for the replica to become available before it proceeds to the next replica.
The above steps are repeated until all of the replicas are restarted.
A controlled switchover is performed. The PostgreSQL Operator determines which replica is the best candidate to become the new primary. It then demotes the primary to become a replica and promotes the best candidate to become the new primary.
The former primary follows a process similar to what is described in step 1.
The downtime is thus constrained to the amount of time the switchover takes.
PGO will automatically detect when to apply a rolling update.
Pod Disruption Budgets
Pods in a Kubernetes cluster can experience voluntary disruptions
as a result of actions initiated by the application owner or a Cluster Administrator. During these
voluntary disruptions Pod Disruption Budgets (PDBs) can be used to ensure that a minimum number of Pods
will be running. The operator allows you to define a minimum number of Pods that should be
available for instance sets and PgBouncer deployments in your postgrescluster. This minimum is
configured in the postgrescluster spec and will be used to create PDBs associated to a resource defined
in the spec. For example, the following spec will create two PDBs, one for instance1 and one for
the PgBouncer deployment:
spec:
instances:
- name: instance1
replicas: 3
minAvailable: 1
proxy:
pgBouncer:
replicas: 3
minAvailable: 1
minAvailable field accepts number (3) or string percentage (50%) values. For more
information see Specifying a PodDisruptionBudget.If minAvailable is set to 0, we will not reconcile a PDB for the resource and any existing PDBs
will be removed. This will effectively disable Pod Disruption Budgets for the resource.
If minAvailable is not provided for an object, a default value will be defined based on the
number of replicas defined for that object. If there is one replica, a PDB will not be created. If
there is more than one replica defined, a minimum of one Pod will be used.