Kubernetes Multi-Cluster Deployments
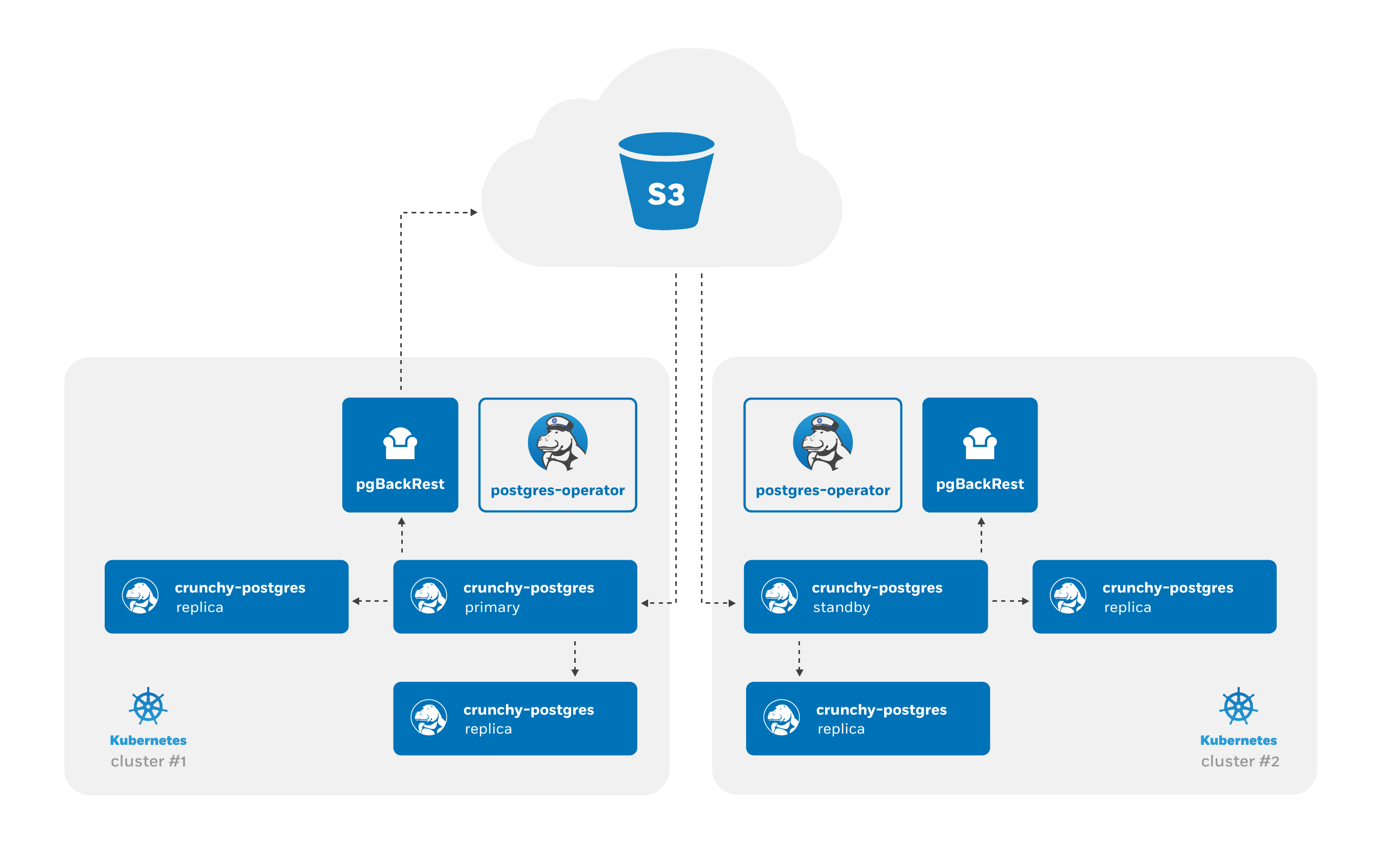
Advanced high-availability and disaster recovery strategies involve spreading your database clusters across multiple data centers to help maximize uptime. In Kubernetes, this technique is known as “federation”. Federated Kubernetes clusters are able to communicate with each other, coordinate changes, and provide resiliency for applications that have high uptime requirements.
As of this writing, federation in Kubernetes is still in ongoing development and is something we monitor with intense interest. As Kubernetes federation continues to mature, we wanted to provide a way to deploy PostgreSQL clusters managed by the PostgreSQL Operator that can span multiple Kubernetes clusters. This can be accomplished with a few environmental setups:
- Two Kubernetes clusters
- S3, or an external storage system that uses the S3 protocol
At a high-level, the PostgreSQL Operator follows the “active-standby” data center deployment model for managing the PostgreSQL clusters across Kuberntetes clusters. In one Kubernetes cluster, the PostgreSQL Operator deploy PostgreSQL as an “active” PostgreSQL cluster, which means it has one primary and one-or-more replicas. In another Kubernetes cluster, the PostgreSQL cluster is deployed as a “standby” cluster: every PostgreSQL instance is a replica.
A side-effect of this is that in each of the Kubernetes clusters, the PostgreSQL Operator can be used to deploy both active and standby PostgreSQL clusters, allowing you to mix and match! While the mixing and matching may not ideal for how you deploy your PostgreSQL clusters, it does allow you to perform online moves of your PostgreSQL data to different Kubernetes clusters as well as manual online upgrades.
Lastly, while this feature does extend high-availability, promoting a standby cluster to an active cluster is not automatic. While the PostgreSQL clusters within a Kubernetes cluster do support self-managed high-availability, a cross-cluster deployment requires someone to specifically promote the cluster from standby to active.
Standby Cluster Overview
Standby PostgreSQL clusters are managed just like any other PostgreSQL cluster
that is managed by the PostgreSQL Operator. For example, adding replicas to a
standby cluster is identical to before: you can use pgo scale.
As the architecture diagram above shows, the main difference is that there is no primary instance: one PostgreSQL instance is reading in the database changes from the S3 repository, while the other replicas are replicas of that instance. This is known as cascading replication. replicas are cascading replicas, i.e. replicas replicating from a database server that itself is replicating from another database server.
Because standby clusters are effectively read-only, certain functionality
that involves making changes to a database, e.g. PostgreSQL user changes, is
blocked while a cluster is in standby mode. Additionally, backups and restores
are blocked as well. While pgBackRest does support
backups from standbys, this requires direct access to the primary database,
which cannot be done until the PostgreSQL Operator supports Kubernetes
federation. If a blocked function is called on a standby cluster via the
pgo client or a direct call to the
API server, the call will return an error.
Key Commands
pgo create cluster
This first step to creating a standby PostgreSQL cluster is…to create a PostgreSQL standby cluster. We will cover how to set this up in the example below, but wanted to provide some of the standby-specific flags that need to be used when creating a standby cluster. These include:
--standby: Creates a cluster as a PostgreSQL standby cluster--password-superuser: The password for thepostgressuperuser account, which performs a variety of administrative actions.--password-replication: The password for the replication account (primaryuser), used to maintain high-availability.--password: The password for the standard user account created during PostgreSQL cluster initialization.--pgbackrest-repo-path: The specific pgBackRest repository path that should be utilized by the standby cluster. Allows a standby cluster to specify a path that matches that of the active cluster it is replicating.--pgbackrest-storage-type: Must be set tos3--pgbackrest-s3-key: The S3 key to use--pgbackrest-s3-key-secret: The S3 key secret to use--pgbackrest-s3-bucket: The S3 bucket to use--pgbackrest-s3-endpoint: The S3 endpoint to use--pgbackrest-s3-region: The S3 region to use
With respect to the credentials, it should be noted that when the standby
cluster is being created within the same Kubernetes cluster AND it has access to
the Kubernetes Secret created for the active cluster, one can use the
--secret-from flag to set up the credentials.
pgo update cluster
pgo update cluster
is responsible for the promotion and disabling of a standby cluster, and
contains several flags to help with this process:
--enable-standby: Enables standby mode in a cluster for a cluster. This will bootstrap a PostgreSQL cluster to become aligned with the current active cluster and begin to follow its changes.--promote-standby: Enables standby mode in a cluster. This is a destructive action that results in the deletion of all PVCs for the cluster (data will be retained according Storage Class and/or Persistent Volume reclaim policies). In order to allow the proper deletion of PVCs, the cluster must also be shutdown.--shutdown: Scales all deployments for the cluster to 0, resulting in a full shutdown of the PG cluster. This includes the primary, any replicas, as well as any supporting services (pgBackRest and pgBouncer if enabled).--startup: Scales all deployments for the cluster to 1, effectively starting a PG cluster that was previously shutdown. This includes the primary, any replicas, as well as any supporting services (pgBackRest and pgBouncer if enabled). The primary is brought online first in order to maintain a consistent primary/replica architecture across startups and shutdowns.
Creating a Standby PostgreSQL Cluster
Let’s create a PostgreSQL deployment that has both an active and standby cluster! You can try this example either within a single Kubernetes cluster, or across multuple Kubernetes clusters.
First, deploy a new active PostgreSQL cluster that is configured to use S3 with pgBackRest. For example:
pgo create cluster hippo --pgbouncer --replica-count=2 \
--pgbackrest-storage-type=local,s3 \
--pgbackrest-s3-key=<redacted> \
--pgbackrest-s3-key-secret=<redacted> \
--pgbackrest-s3-bucket=watering-hole \
--pgbackrest-s3-endpoint=s3.amazonaws.com \
--pgbackrest-s3-region=us-east-1 \
--password-superuser=supersecrethippo \
--password-replication=somewhatsecrethippo \
--password=opensourcehippo
(Replace the placeholder values with your actual values. We are explicitly setting all of the passwords for the primary cluster to make it easier to run the example as is).
The above command creates an active PostgreSQL cluster with two replicas and a pgBouncer deployment. Wait a few moments for this cluster to become live before proceeding.
Once the cluster has been created, you can then create the standby cluster. This can either be in another Kubernetes cluster or within the same Kubernetes cluster. If using a separate Kubernetes cluster, you will need to provide the proper passwords for the superuser and replication accounts. You can also provide a password for the regular PostgreSQL database user created during cluster initialization to ensure the passwords and associated secrets across both clusters are consistent.
(If the standby cluster is being created using the same PostgreSQL Operator
deployment (and therefore the same Kubernetes cluster), the --secret-from flag
can also be used in lieu of these passwords. You would specify the name of the
cluster [e.g. hippo] as the value of the --secret-from variable.)
With this in mind, create a standby cluster similar to this below:
pgo create cluster hippo-standby --standby --pgbouncer --replica-count=2 \
--pgbackrest-storage-type=s3 \
--pgbackrest-s3-key=<redacted> \
--pgbackrest-s3-key-secret=<redacted> \
--pgbackrest-s3-bucket=watering-hole \
--pgbackrest-s3-endpoint=s3.amazonaws.com \
--pgbackrest-s3-region=us-east-1 \
--pgbackrest-repo-path=/backrestrepo/hippo-backrest-shared-repo \
--password-superuser=supersecrethippo \
--password-replication=somewhatsecrethippo \
--password=opensourcehippo
Note the use of the --pgbackrest-repo-path flag as it points to the name of
the pgBackRest repository that is used for the original hippo cluster.
At this point, the standby cluster will bootstrap as a standby along with two
cascading replicas. pgBouncer will be deployed at this time as well, but will
remain non-functional until hippo-standby is promoted. To see that the Pod is
indeed a standby, you can check the logs.
kubectl logs hippo-standby-dcff544d6-s6d58
…
Thu Mar 19 18:16:54 UTC 2020 INFO: Node standby-dcff544d6-s6d58 fully initialized for cluster standby and is ready for use
2020-03-19 18:17:03,390 INFO: Lock owner: standby-dcff544d6-s6d58; I am standby-dcff544d6-s6d58
2020-03-19 18:17:03,454 INFO: Lock owner: standby-dcff544d6-s6d58; I am standby-dcff544d6-s6d58
2020-03-19 18:17:03,598 INFO: no action. i am the standby leader with the lock
2020-03-19 18:17:13,389 INFO: Lock owner: standby-dcff544d6-s6d58; I am standby-dcff544d6-s6d58
2020-03-19 18:17:13,466 INFO: no action. i am the standby leader with the lock
You can also see that this is a standby cluster from the
pgo show cluster
command.
pgo show cluster hippo
cluster : standby (crunchy-postgres-ha:centos7-12.4-4.5.0)
standby : true
Promoting a Standby Cluster
There comes a time where a standby cluster needs to be promoted to an active cluster. Promoting a standby cluster means that a PostgreSQL instance within it will become a priary and start accepting both reads and writes. This has the net effect of pushing WAL (transaction archives) to the pgBackRest repository, so we need to take a few steps first to ensure we don’t accidentally create a split-brain scenario.
First, if this is not a disaster scenario, you will want to “shutdown” the
active PostgreSQL cluster. This can be done with the --shutdown flag:
pgo update cluster hippo --shutdown
The effect of this is that all the Kubernetes Deployments for this cluster are scaled to 0. You can verify this with the following command:
kubectl get deployments --selector pg-cluster=hippo
NAME READY UP-TO-DATE AVAILABLE AGE
hippo 0/0 0 0 32m
hippo-backrest-shared-repo 0/0 0 0 32m
hippo-kvfo 0/0 0 0 27m
hippo-lkge 0/0 0 0 27m
hippo-pgbouncer 0/0 0 0 31m
We can then promote the standby cluster using the --promote-standby flag:
pgo update cluster hippo-standby --promote-standby
This command essentially removes the standby configuration from the Kubernetes cluster’s DCS, which triggers the promotion of the current standby leader to a primary PostgreSQL instance. You can view this promotion in the PostgreSQL standby leader’s (soon to be active leader’s) logs:
kubectl logs hippo-standby-dcff544d6-s6d58
…
2020-03-19 18:28:11,919 INFO: Reloading PostgreSQL configuration.
server signaled
2020-03-19 18:28:16,792 INFO: Lock owner: standby-dcff544d6-s6d58; I am standby-dcff544d6-s6d58
2020-03-19 18:28:16,850 INFO: Reaped pid=5377, exit status=0
2020-03-19 18:28:17,024 INFO: no action. i am the leader with the lock
2020-03-19 18:28:26,792 INFO: Lock owner: standby-dcff544d6-s6d58; I am standby-dcff544d6-s6d58
2020-03-19 18:28:26,924 INFO: no action. i am the leader with the lock
As pgBouncer was enabled for the cluster, the pgbouncer user’s password is
rotated, which will bring pgBouncer online with the newly promoted active
cluster. If pgBouncer is still having trouble connecting, you can explicitly
rotate the password with the following command:
pgo update pgbouncer --rotate-password hippo-standby
With the standby cluster now promoted, the cluster with the original active PostgreSQL cluster can now be turned into a standby PostgreSQL cluster. This is done by deleting and recreating all PVCs for the cluster and re-initializing it as a standby using the S3 repository. Being that this is a destructive action (i.e. data will only be retained if any Storage Classes and/or Persistent Volumes have the appropriate reclaim policy configured) a warning is shown when attempting to enable standby.
pgo update cluster hippo --enable-standby
Enabling standby mode will result in the deletion of all PVCs for this cluster!
Data will only be retained if the proper retention policy is configured for any associated storage classes and/or persistent volumes.
Please proceed with caution.
WARNING: Are you sure? (yes/no): yes
updated pgcluster hippo
To verify that standby has been enabled, you can check the DCS configuration for the cluster to verify that the proper standby settings are present.
kubectl get cm hippo-config -o yaml | grep standby
%f \"%p\""},"use_pg_rewind":true,"use_slots":false},"standby_cluster":{"create_replica_methods":["pgbackrest_standby"],"restore_command":"source
Also, the PVCs for the cluster should now only be a few seconds old, since they were recreated.
kubectl get pvc --selector pg-cluster=hippo
NAME STATUS VOLUME CAPACITY AGE
hippo Bound crunchy-pv251 1Gi 33s
hippo-kvfo Bound crunchy-pv174 1Gi 29s
hippo-lkge Bound crunchy-pv228 1Gi 26s
hippo-pgbr-repo Bound crunchy-pv295 1Gi 22s
And finally, the cluster can be restarted:
pgo update cluster hippo --startup
At this point, the cluster will reinitialize from scratch as a standby, just like the original standby that was created above. Therefore any transactions written to the original standby, should now replicate back to this cluster.