Overview
The goal of the Crunchy PostgreSQL Operator is to provide a means to quickly get your applications up and running on PostgreSQL for both development and production environments. To understand how the PostgreSQL Operator does this, we want to give you a tour of its architecture, with explains both the architecture of the PostgreSQL Operator itself as well as recommended deployment models for PostgreSQL in production!
Crunchy PostgreSQL Operator Architecture
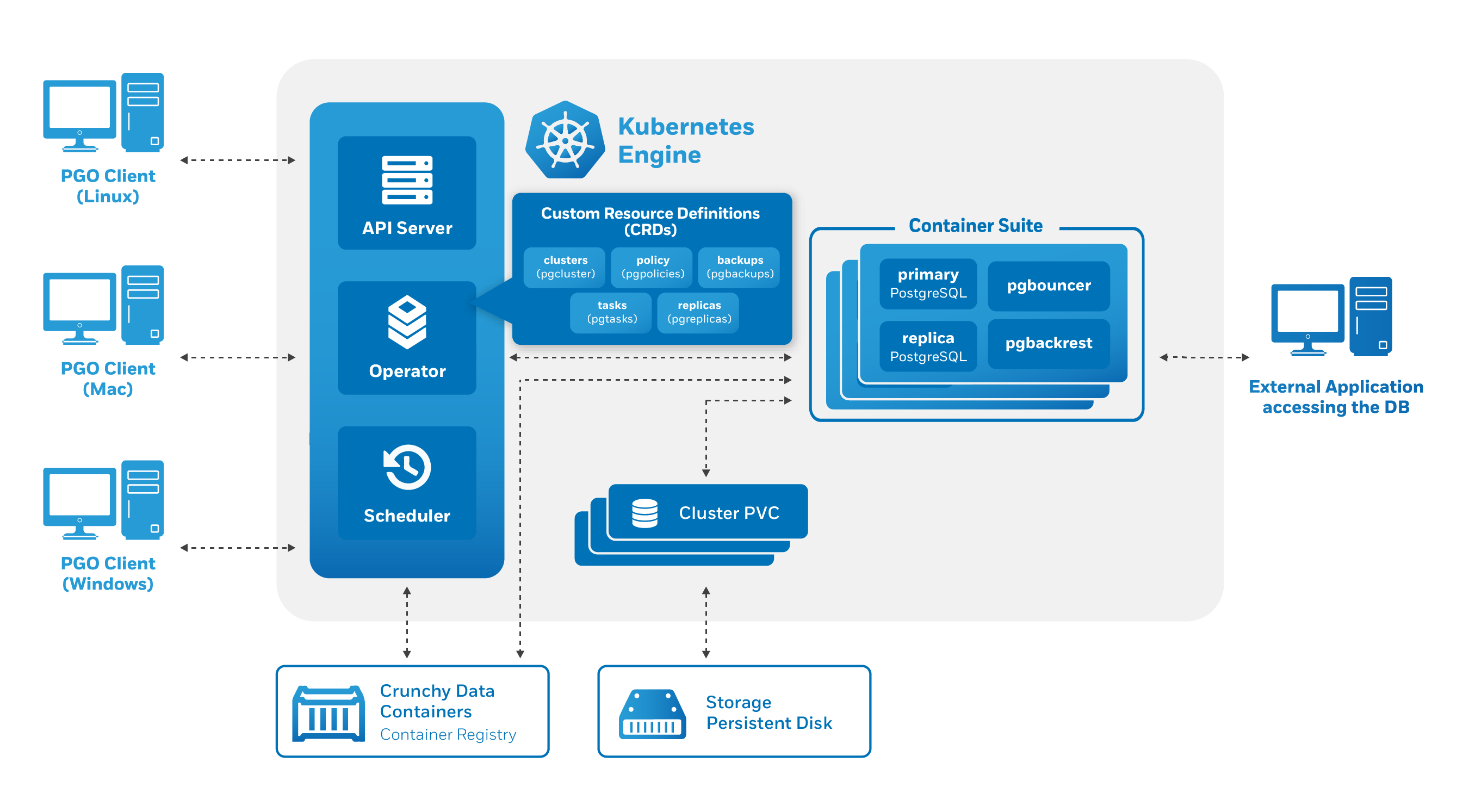
The Crunchy PostgreSQL Operator extends Kubernetes to provide a higher-level abstraction for rapid creation and management of PostgreSQL clusters. The Crunchy PostgreSQL Operator leverages a Kubernetes concept referred to as “Custom Resources” to create several custom resource definitions (CRDs) that allow for the management of PostgreSQL clusters.
The Custom Resource Definitions include:
pgclusters.crunchydata.com: Stores information required to manage a PostgreSQL cluster. This includes things like the cluster name, what storage and resource classes to use, which version of PostgreSQL to run, information about how to maintain a high-availability cluster, etc.pgreplicas.crunchydata.com: Stores information required to manage the replicas within a PostgreSQL cluster. This includes things like the number of replicas, what storage and resource classes to use, special affinity rules, etc.pgtasks.crunchydata.com: A general purpose CRD that accepts a type of task that is needed to run against a cluster (e.g. create a cluster, take a backup, perform a clone) and tracks the state of said task throw its workflow.pgpolicies.crunchydata.com: Stores a reference to a SQL file that can be executed against a PostgreSQL cluster. In the past, this was used to manage RLS policies on PostgreSQL clusters.
There are also a few legacy Custom Resource Definitions that the PostgreSQL Operator comes with that will be removed in a future release.
The PostgreSQL Operator runs as a deployment in a namespace and is composed of up to four Pods, including:
operator(image: postgres-operator) - This is the heart of the PostgreSQL Operator. It contains a series of Kubernetes controllers that place watch events on a series of native Kubernetes resources (Jobs, Pods) as well as the Custom Resources that come with the PostgreSQL Operator (Pgcluster, Pgtask)apiserver(image: pgo-apiserver) - This provides an API that a PostgreSQL Operator User (pgouser) can interface with via thepgocommand-line interface (CLI) or directly via HTTP requests. The API server can also control what resources a user can access via a series of RBAC rules that can be defined as part of apgorole.scheduler(image: pgo-scheduler) - A container that runscronand allows a user to schedule repeatable tasks, such as backups (because it is important to schedule backups in a production environment!)event(image: pgo-event, optional) - A container that provides an interface to thensqmessage queue and transmits information about lifecycle events that occur within the PostgreSQL Operator (e.g. a cluster is created, a backup is taken, a clone fails to create)
The main purpose of the PostgreSQL Operator is to create and update information around the structure of a PostgreSQL Cluster, and to relay information about the overall status and health of a PostgreSQL cluster. The goal is to also simplify this process as much as possible for users. For example, let’s say we want to create a high-availability PostgreSQL cluster that has a single replica, supports having backups in both a local storage area and Amazon S3 and has built-in metrics and connection pooling, similar to:
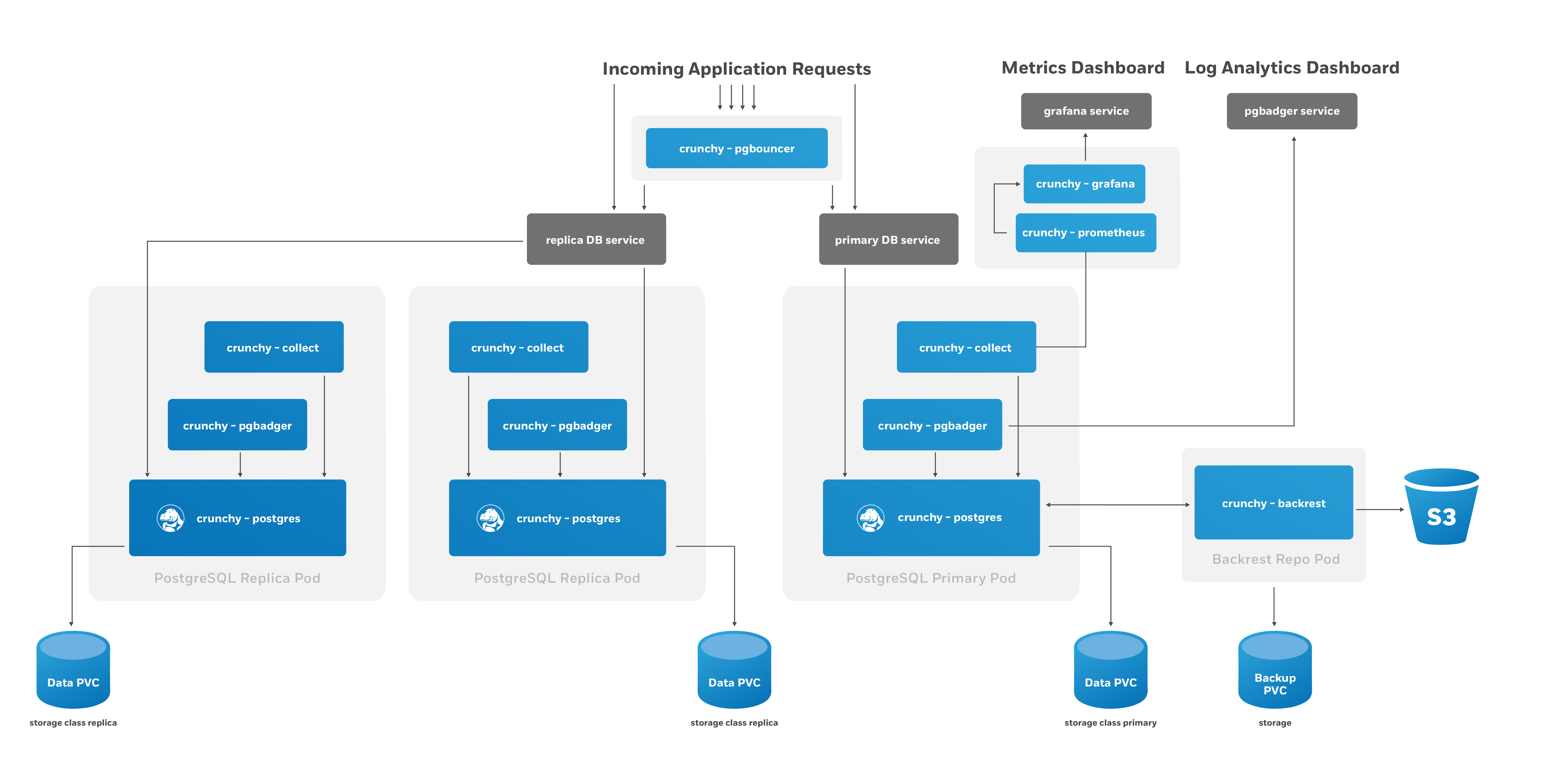
We can accomplish that with a single command:
pgo create cluster hacluster --replica-count=1 --metrics --pgbackrest-storage-type="local,s3" --pgbouncer --pgbadgerThe PostgreSQL Operator handles setting up all of the various Deployments and sidecars to be able to accomplish this task, and puts in the various constructs to maximize resiliency of the PostgreSQL cluster.
You will also notice that high-availability is enabled by default. The Crunchy PostgreSQL Operator uses a distributed-consensus method for PostgreSQL cluster high-availability, and as such delegates the management of each cluster’s availability to the clusters themselves. This removes the PostgreSQL Operator from being a single-point-of-failure, and has benefits such as faster recovery times for each PostgreSQL cluster. For a detailed discussion on high-availability, please see the High-Availability section.
Every single Kubernetes object (Deployment, Service, Pod, Secret, Namespace,
etc.) that is deployed or managed by the PostgreSQL Operator has a Label
associated with the name of vendor and a value of crunchydata. You can
use Kubernetes selectors to easily find out which objects are being watched by
the PostgreSQL Operator. For example, to get all of the managed Secrets in the
default namespace the PostgreSQL Operator is deployed into (pgo):
kubectl get secrets -n pgo --selector=vendor=crunchydataKubernetes Deployments: The Crunchy PostgreSQL Operator Deployment Model
The Crunchy PostgreSQL Operator uses Kubernetes Deployments for running PostgreSQL clusters instead of StatefulSets or other objects. This is by design: Kubernetes Deployments allow for more flexibility in how you deploy your PostgreSQL clusters.
For example, let’s look at a specific PostgreSQL cluster where we want to have one primary instance and one replica instance. We want to ensure that our primary instance is using our fastest disks and has more compute resources available to it. We are fine with our replica having slower disks and less compute resources. We can create this envirionment with a command similar to below:
pgo create cluster mixed --replica-count=1 \
--storage-config=fast --resources-config=large \
--replica-storage-config=standard --resources-config=mediumNow let’s say we want to have one replica available to run read-only queries against, but we want its hardware profile to mirror that of the primary instance. We can run the following command:
pgo scale mixed --replica-count=1 \
--storage-config=fast --resources-config=largeKubernetes Deployments allow us to create heterogeneous clusters with ease and let us scale them up and down as we please. Additional components in our PostgreSQL cluster, such as the pgBackRest repository or an optional pgBouncer, are deployed as Kubernetes Deployments as well.
We can also leverage Kubernees Deployments to apply Node Affinity rules to individual PostgreSQL instances. For instance, we may want to force one or more of our PostgreSQL replicas to run on Nodes in a different region than our primary PostgreSQL instances.
Using Kubernetes Deployments does create additional management complexity, but the good news is: the PostgreSQL Operator manages it for you! Being aware of this model can help you understand how the PostgreSQL Operator gives you maximum flexibility in for your PostgreSQL clusters while giving you the tools to troubleshoot issues in production.
The last piece of this model is the use of Kubernetes Services for accessing your PostgreSQL clusters and their various components. The PostgreSQL Operator puts services in front of each Deployment to ensure you have a known, consistent means of accessing your PostgreSQL components.
Note that in some production environments, there can be delays in accessing Services during transition events. The PostgreSQL Operator attempts to mitigate delays during critical operations (e.g. failover, restore, etc.) by directly accessing the Kubernetes Pods to perform given actions.
For a detailed analysis, please see Using Kubernetes Deployments for Running PostgreSQL.
Additional Architecture Information
There is certainly a lot to unpack in the overall architecture of the Crunchy PostgreSQL Operator. Understanding the architecture will help you to plan the deployment model that is best for your environment. For more information on the architectures of various components of the PostgreSQL Operator, please read onward!