Feature Overview
This topic describes the features of Crunchy PostgreSQL for Pivotal Cloud Foundry (PCF) Tile.
Plans
The Crunchy PostgreSQL for Pivotal Cloud Foundry (PCF) Tile offers several out-of-the-box (configurable) plans. When deploying the service, operators have the opportunity to tune these plans for the needs of the environment.
Plan Sizes
The postgresql-13-odb service comes with several preconfigured plans.
Each plan corresponds to different server size set up by the operator when the service was deployed.
The following table provides information about the out-of-the-box cluster configurations. Review each plan offering and choose the correct database plan for the application.
| Plan Name | Description |
|---|---|
standalone |
Single PostgreSQL server, useful for small development purposes |
standalone-replica |
Single PostgreSQL server configured as a remote replica for an existing parent service |
general |
Standard service plan, configured to fit most general use cases |
custom |
Uses similar general plan settings, configurable to specific use cases |
general-monitor |
Same as general, but with added support for Grafana monitoring |
custom-monitor |
Same as custom but with added support for Grafana monitoring |
- The number of replicas are only configurable during initial setup.
- All replicas use
asyncreplication.syncreplication is not yet configurable. - Standalone instances should be used with care, as they lack any of the integrated backup or recovery systems provided in the General plans.
Part of maintaining high availability is having room to grow the database. Therefore, operators and developers should consider the rate at which they expect to grow and select an appropriately sized plan.
Standalone Plan
The standalone plan includes a single PostgreSQL instance without the HA
and load balancing features outlined below. Archiving and automated
backups are disabled by default, but can be enabled by setting
standalone_backups to true during service creation or update.
Standalone plans will not work with the Crunchy PostgreSQL Manager app.
Standalone Replica Plan
The standalone-replica plan leverages the standalone instance as a very basic remote replica. All of the restrictions for the Standalone plan apply to this service plan. The standalone-replica service must be accessible from the parent cluster; it must be in the same PCF instance, or the networks must be peered.
See Load Balancing and Selectively Accessing Clusters for more information.
Standalone Replica plans will not work with the Crunchy PostgreSQL Manager app.
Automated Backups
Crunchy PostgreSQL for Pivotal Cloud Foundry (PCF) Tile uses pgBackRest as a dedicated backup and archiving host. The tile comes pre-configured with nightly physical backups of the database server for non-standalone plans:
| Backup Type | Day | Time |
|---|---|---|
| Full | Sunday | 1 am UTC |
| Incremental | Monday | 1 am UTC |
| Incremental | Tuesday | 1 am UTC |
| Incremental | Wednesday | 1 am UTC |
| Incremental | Thursday | 1 am UTC |
| Incremental | Friday | 1 am UTC |
| Incremental | Saturday | 1 am UTC |
Archiving and backups are disabled by default in the
standalone plan. PCF users can set the standalone_backups parameter
to true to enable this feature.Although backups only happen once a day, PostgreSQL is continuously shipping the Write-Ahead-Logs (WAL) to the pgBackrest server. This means that point-in-time recovery is possible, regardless of the schedule.
These backups not only offer peace of mind, but are used frequently by the tile.
Crunchy PostgreSQL for PCF uses backups to create replicas in the stack. By using backups in operations, we ensure that backup and restore operations are functioning properly.
All archives from the database server are stored on the dedicated backup host. This means that databases can be restored to specific points in time.
Currently, individual databases cannot be restored. All databases are restored in the shared cluster.
Standalone plans do not include automatic backups by default. When using a standalone plan, you should regularly perform manual backups using external tools, or enable the backup using the service creation/update parameter.
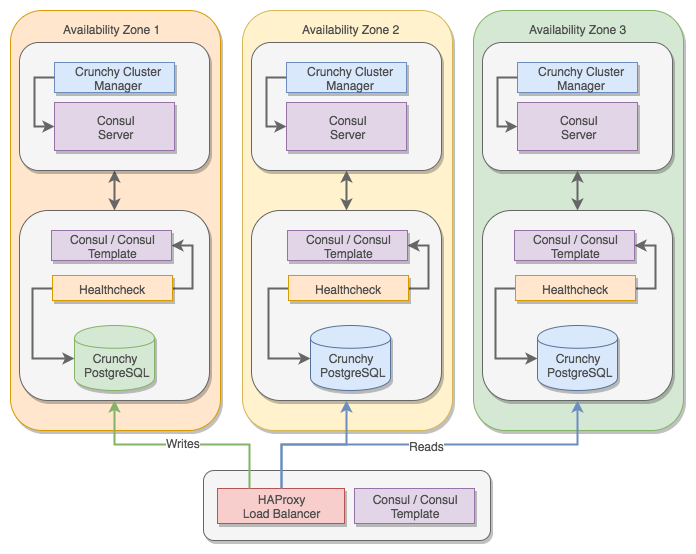
Load Balancing
Crunchy PostgreSQL for PCF uses HAProxy as a single point of entry to the database cluster. App developers must switch ports depending on the type of cluster they want to interact with.
Selectively Accessing Clusters
By using port switching, apps have the ability to manage the types of database interactions their app needs. When used correctly, this strategy allows apps to be more performant.
To query a primary node, apps must use the 5432 port on the load
balancer. This ensures that writes or reads are redirected to the
primary cluster.
To query a replica node, apps must use the 5433 port on the load
balancer. This ensures that reads are redirected to the replicas.
It is not possible to select an individual replica, so all connections
will be shared across all replicas in a ‘round-robin’ format. For this
reason, when explicitly accessing replicas, it is important to ensure
the total number of connections to these replicas do not exceed the
max_connections parameter.
High Availability Model
Crunchy PostgreSQL for PCF provisions a cluster of PostgreSQL servers and self-configures their roles (primary and many replicas). This allows the servers to change their roles when failures are detected.
Crunchy PostgreSQL for PCF configuration files are managed by
consul-template. Each of these templates watch different parts of the
stack. When changes are detected, configuration files automatically are
rendered with the latest state. This allows the system to be dynamic and
change depending on state of services.
For example, the PostgreSQL load balancer automatically detects when replicas are added or removed, and reconfigures its pool to reflect the current state.
Automatic Failover
Crunchy Cluster Manager runs on each of the Consul Servers within the Crunchy PostgreSQL for PCF. The job of CCM is to detect failures of the PostgreSQL servers and to determine who is the best candidate to replace a failed primary.
Once a new primary role is elected, CCM updates the Consul Service Catalog to reflect the new state. The newly elected primary reconfigures itself (triggers a failover) and all other services detect the new primary.
Failed former primaries are put into a fenced state. This tells the rest
of the stack to no longer communicate with the failed service. An hourly
cron job attempts to repair fenced servers and add them to the replica
pool.
Tools
Crunchy PostgreSQL for PCF offers the following tools to help developers manage their system:
- Crunchy PostgreSQL Manager for PCF (crunchy-postgresql-manager)
- pgAdmin4 for Crunchy PostgreSQL for PCF (cf-pgAdmin4)
- Crunchy Data Loader
- Grafana for Crunchy PostgreSQL for PCF (cf-grafana)