Common pgo Client Tasks
While the full pgo client reference will tell you
everything you need to know about how to use pgo, it may be helpful to see
several examples on how to conduct “day-in-the-life” tasks for administrating
PostgreSQL cluster with the PostgreSQL Operator.
The below guide covers many of the common operations that are required when managing PostgreSQL clusters. The guide is broken up by different administrative topics, such as provisioning, high-availability, etc.
Setup Before Running the Examples
Many of the pgo client commands require you to specify a namespace via the
-n or --namespace flag. While this is a very helpful tool when managing
PostgreSQL deployxments across many Kubernetes namespaces, this can become
onerous for the intents of this guide.
If you install the PostgreSQL Operator using the quickstart
guide, you will have two namespaces installed: pgouser1 and pgouser2. We
can choose to always use one of these namespaces by setting the PGO_NAMESPACE
environmental variable, which is detailed in the global pgo Client
reference,
For convenience, we will use the pgouser1 namespace in the examples below.
For even more convenience, we recommend setting pgouser1 to be the value of
the PGO_NAMESPACE variable. In the shell that you will be executing the pgo
commands in, run the following command:
export PGO_NAMESPACE=pgouser1If you do not wish to set this environmental variable, or are in an environment
where you are unable to use environmental variables, you will have to use the
--namespace (or -n) flag for most commands, e.g.
pgo version -n pgouser1
JSON Output
The default for the pgo client commands is to output their results in a
readable format. However, there are times where it may be helpful to you to have
the format output in a machine parseable format like JSON.
Several commands support the -o/--output flags that delivers the results of
the command in the specified output. Presently, the only output that is
supported is json.
As an example of using this feature, if you wanted to get the results of the
pgo test command in JSON, you could run the following:
pgo test hacluster -o jsonPostgreSQL Operator System Basics
To get started, it’s first important to understand the basics of working with the PostgreSQL Operator itself. You should know how to test if the PostgreSQL Operator is working, check the overall status of the PostgreSQL Operator, view the current configuration that the PostgreSQL Operator us using, and seeing which Kubernetes Namespaces the PostgreSQL Operator has access to.
While this may not be as fun as creating high-availability PostgreSQL clusters, these commands will help you to perform basic troubleshooting tasks in your environment.
Checking Connectivity to the PostgreSQL Operator
A common task when working with the PostgreSQL Operator is to check connectivity
to the PostgreSQL Operator. This can be accomplish with the pgo version
command:
pgo versionwhich, if working, will yield results similar to:
pgo client version 4.3.0
pgo-apiserver version 4.3.0
Inspecting the PostgreSQL Operator Configuration
The pgo show config command allows you to
view the current configuration that the PostgreSQL Operator is using. This can
be helpful for troubleshooting issues such as which PostgreSQL images are being
deployed by default, which storage classes are being used, etc.
You can run the pgo show config command by running:
pgo show configwhich yields output similar to:
BasicAuth: ""
Cluster:
CCPImagePrefix: crunchydata
CCPImageTag: centos7-12.2-4.3.0
Policies: ""
Metrics: false
Badger: false
Port: "5432"
PGBadgerPort: "10000"
ExporterPort: "9187"
User: testuser
Database: userdb
PasswordAgeDays: "60"
PasswordLength: "8"
Replicas: "0"
ServiceType: ClusterIP
BackrestPort: 2022
Backrest: true
BackrestS3Bucket: ""
BackrestS3Endpoint: ""
BackrestS3Region: ""
DisableAutofail: false
PgmonitorPassword: ""
EnableCrunchyadm: false
DisableReplicaStartFailReinit: false
PodAntiAffinity: preferred
SyncReplication: false
Pgo:
Audit: false
PGOImagePrefix: crunchydata
PGOImageTag: centos7-4.3.0
PrimaryStorage: nfsstorage
BackupStorage: nfsstorage
ReplicaStorage: nfsstorage
BackrestStorage: nfsstorage
Storage:
nfsstorage:
AccessMode: ReadWriteMany
Size: 1G
StorageType: create
StorageClass: ""
SupplementalGroups: "65534"
MatchLabels: ""Viewing PostgreSQL Operator Key Metrics
The pgo status command provides a
generalized statistical view of the overall resource consumption of the
PostgreSQL Operator. These stats include:
- The total number of PostgreSQL instances
- The total number of Persistent Volume Claims (PVC) that are allocated, along with the total amount of disk the claims specify
- The types of container images that are deployed, along with how many are deployed
- The nodes that are used by the PostgreSQL Operator
and more
You can use the pgo status command by running:
pgo statuswhich yields output similar to:
Operator Start: 2019-12-26 17:53:45 +0000 UTC
Databases: 8
Claims: 8
Total Volume Size: 8Gi
Database Images:
4 crunchydata/crunchy-postgres-ha:centos7-12.2-4.3.0
4 crunchydata/pgo-backrest-repo:centos7-4.3.0
8 crunchydata/pgo-backrest:centos7-4.3.0
Databases Not Ready:
Labels (count > 1): [count] [label]
[8] [vendor=crunchydata]
[4] [pgo-backrest-repo=true]
[4] [pgouser=pgoadmin]
[4] [pgo-pg-database=true]
[4] [crunchy_collect=false]
[4] [pg-pod-anti-affinity=]
[4] [pgo-version=4.3.0]
[4] [archive-timeout=60]
[2] [pg-cluster=hacluster]
Viewing PostgreSQL Operator Managed Namespaces
The PostgreSQL Operator has the ability to manage PostgreSQL clusters across Kubernetes Namespaces. During the course of Operations, it can be helpful to know which namespaces the PostgreSQL Operator can use for deploying PostgreSQL clusters.
You can view which namespaces the PostgreSQL Operator can utilize by using
the pgo show namespace command. To
list out the namespaces that the PostgreSQL Operator has access to, you can run
the following command:
pgo show namespace --allwhich yields output similar to:
pgo username: pgoadmin
namespace useraccess installaccess
default accessible no access
kube-node-lease accessible no access
kube-public accessible no access
kube-system accessible no access
pgo accessible no access
pgouser1 accessible accessible
pgouser2 accessible accessible
somethingelse no access no access
NOTE: Based on your deployment, your Kubernetes administrator may restrict
access to the multi-namespace feature of the PostgreSQL Operator. In this case,
you do not need to worry about managing your namespaces and as such do not need
to use this command, but we recommend setting the PGO_NAMESPACE variable as
described in the general notes on this page.
Provisioning: Create, View, Destroy
Creating a PostgreSQL Cluster
You can create a cluster using the pgo create cluster
command:
pgo create cluster haclusterwhich if successfully, will yield output similar to this:
created Pgcluster hacluster
workflow id ae714d12-f5d0-4fa9-910f-21944b41dec8
Create a PostgreSQL Cluster with Different PVC Sizes
You can also create a PostgreSQL cluster with an arbitrary PVC size using the
pgo create cluster command. For
example, if you want to create a PostgreSQL cluster with with a 128GB PVC, you
can use the following command:
pgo create cluster hacluster --pvc-size=128GiThe above command sets the PVC size for all PostgreSQL instances in the cluster, i.e. the primary and replicas.
This also extends to the size of the pgBackRest repository as well, if you are using the local Kubernetes cluster storage for your backup repository. To create a PostgreSQL cluster with a pgBackRest repository that uses a 1TB PVC, you can use the following command:
pgo create cluster hacluster --pgbackrest-pvc-size=1TiSpecify CPU / Memory for a PostgreSQL Cluster
To specify the amount of CPU and memory to request for a PostgreSQL cluster, you
can use the --cpu and --memory flags of the
pgo create cluster command. Both
of these values utilize the Kubernetes quantity format
for specifying how to allocate resources.
For example, to create a PostgreSQL cluster that requests 4 CPU cores and has 16 gibibytes of memory, you can use the following command:
pgo create cluster hacluster --cpu=4 --memory=16GiCreate a PostgreSQL Cluster with PostGIS
To create a PostgreSQL cluster that uses the geospatial extension PostGIS, you can execute the following command:
pgo create cluster hagiscluster --ccp-image=crunchy-postgres-gis-haCreate a PostgreSQL Cluster with a Tablespace
Tablespaces are a PostgreSQL feature that allows a user to select specific volumes to store data to, which is helpful in several types of scenarios. Often your workload does not require a tablespace, but the PostgreSQL Operator provides support for tablespaces throughout the lifecycle of a PostgreSQL cluster.
To create a PostgreSQL cluster that uses the tablespace feature with NFS storage, you can execute the following command:
pgo create cluster hactsluster --tablespace=name=ts1:storageconfig=nfsstorageYou can use your preferred storage engine instead of nfsstorage. For example,
to create multiple tablespaces on GKE, you can execute the following command:
pgo create cluster hactsluster \
--tablespace=name=ts1:storageconfig=gce \
--tablespace=name=ts2:storageconfig=gceTablespaces are immediately available once the PostgreSQL cluster is
provisioned. For example, to create a table using the tablespace ts1, you can
run the following SQL on your PostgreSQL cluster:
CREATE TABLE sensor_data (
id int GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
sensor1 numeric,
sensor2 numeric,
sensor3 numeric,
sensor4 numeric
)
TABLESPACE ts1;You can also create tablespaces that have different sized PVCs from the ones defined in the storage specification. For instance, to create two tablespaces, one that uses a 10GiB PVC and one that uses a 20GiB PVC, you can execute the following command:
pgo create cluster hactsluster \
--tablespace=name=ts1:storageconfig=gce:pvcsize=10Gi \
--tablespace=name=ts2:storageconfig=gce:pvcsize=20GiTracking a Newly Provisioned Cluster
A new PostgreSQL cluster can take a few moments to provision. You may have
noticed that the pgo create cluster command returns something called a
“workflow id”. This workflow ID allows you to track the progress of your new
PostgreSQL cluster while it is being provisioned using the pgo show workflow
command:
pgo show workflow ae714d12-f5d0-4fa9-910f-21944b41dec8which can yield output similar to:
parameter value
--------- -----
pg-cluster hacluster
task completed 2019-12-27T02:10:14Z
task submitted 2019-12-27T02:09:46Z
workflowid ae714d12-f5d0-4fa9-910f-21944b41dec8
View PostgreSQL Cluster Details
To see details about your PostgreSQL cluster, you can use the pgo show cluster
command. These details include elements such as:
- The version of PostgreSQL that the cluster is using
- The PostgreSQL instances that comprise the cluster
- The Pods assigned to the cluster for all of the associated components, including the nodes that the pods are assigned to
- The Persistent Volume Claims (PVC) that are being consumed by the cluster
- The Kubernetes Deployments associated with the cluster
- The Kubernetes Services associated with the cluster
- The Kubernetes Labels that are assigned to the PostgreSQL instances
and more.
You can view the details of the cluster by executing the following command:
pgo show cluster haclusterwhich will yield output similar to:
cluster : hacluster (crunchy-postgres-ha:centos7-12.2-4.3.0)
pod : hacluster-6dc6cfcfb9-f9knq (Running) on node01 (1/1) (primary)
pvc : hacluster
resources : CPU Limit= Memory Limit=, CPU Request= Memory Request=
storage : Primary=200M Replica=200M
deployment : hacluster
deployment : hacluster-backrest-shared-repo
service : hacluster - ClusterIP (10.102.20.42)
labels : pg-pod-anti-affinity= archive-timeout=60 crunchy-pgbadger=false crunchy_collect=false deployment-name=hacluster pg-cluster=hacluster crunchy-pgha-scope=hacluster autofail=true pgo-backrest=true pgo-version=4.3.0 current-primary=hacluster name=hacluster pgouser=pgoadmin workflowid=ae714d12-f5d0-4fa9-910f-21944b41dec8
Deleting a Cluster
You can delete a PostgreSQL cluster that is managed by the PostgreSQL Operator by executing the following command:
pgo delete cluster haclusterThis will remove the cluster from being managed by the PostgreSQL Operator, as well as delete the root data Persistent Volume Claim (PVC) and backup PVCs associated with the cluster.
If you wish to keep your PostgreSQL data PVC, you can delete the cluster with the following command:
pgo delete cluster hacluster --keep-dataYou can then recreate the PostgreSQL cluster with the same data by using the
pgo create cluster command with a cluster of the same name:
pgo create cluster haclusterThis technique is used when performing tasks such as upgrading the PostgreSQL Operator.
You can also keep the pgBackRest repository associated with the PostgreSQL
cluster by using the --keep-backups flag with the pgo delete cluster
command:
pgo delete cluster hacluster --keep-backupsTesting PostgreSQL Cluster Availability
You can test the availability of your cluster by using the pgo test
command. The pgo test command checks to see if the Kubernetes Services and
the Pods that comprise the PostgreSQL cluster are available to receive
connections. This includes:
- Testing that the Kubernetes Endpoints are available and able to route requests to healthy Pods
- Testing that each PostgreSQL instance is available and ready to accept client
connections by performing a connectivity check similar to the one performed by
pg_isready
To test the availability of a PostgreSQL cluster, you can run the following command:
pgo test haclusterwhich will yield output similar to:
cluster : hacluster
Services
primary (10.102.20.42:5432): UP
Instances
primary (hacluster-6dc6cfcfb9-f9knq): UP
Disaster Recovery: Backups & Restores
The PostgreSQL Operator supports sophisticated functionality for managing your backups and restores. For more information for how this works, please see the disaster recovery guide.
Creating a Backup
The PostgreSQL Operator uses the open source pgBackRest backup and recovery utility for managing backups and PostgreSQL archives. These backups are also used as part of managing the overall health and high-availability of PostgreSQL clusters managed by the PostgreSQL Operator and used as part of the cloning process as well.
When a new PostgreSQL cluster is provisioned by the PostgreSQL Operator, a full
pgBackRest backup is taken by default. This is required in order to create new
replicas (via pgo scale) for the PostgreSQL cluster as well as healing during
a failover scenario.
To create a backup, you can run the following command:
pgo backup haclusterwhich by default, will create an incremental pgBackRest backup. The reason for this is that the PostgreSQL Operator initially creates a pgBackRest full backup when the cluster is initial provisioned, and pgBackRest will take incremental backups for each subsequent backup until a different backup type is specified.
Most pgBackRest options are supported and can be passed in by the PostgreSQL
Operator via the --backup-opts flag. What follows are some examples for how
to utilize pgBackRest with the PostgreSQL Operator to help you create your
optimal disaster recovery setup.
Creating a Full Backup
You can create a full backup using the following command:
pgo backup hacluster --backup-opts="--type=full"Creating a Differential Backup
You can create a differential backup using the following command:
pgo backup hacluster --backup-opts="--type=diff"Creating an Incremental Backup
You can create a differential backup using the following command:
pgo backup hacluster --backup-opts="--type=incr"An incremental backup is created without specifying any options after a full or differential backup is taken.
Creating Backups in S3
The PostgreSQL Operator supports creating backups in S3 or any object storage system that uses the S3 protocol. For more information, please read the section on PostgreSQL Operator Backups with S3 in the architecture section.
Displaying Backup Information
You can see information about the current state of backups in a PostgreSQL cluster managed by the PostgreSQL Operator by executing the following command:
pgo show backup haclusterSetting Backup Retention
By default, pgBackRest will allow you to keep on creating backups until you run out of disk space. As such, it may be helpful to manage how many backups are retained.
pgBackRest comes with several flags for managing how backups can be retained:
--repo1-retention-full: how many full backups to retain--repo1-retention-diff: how many differential backups to retain--repo1-retention-archive: how many sets of WAL archives to retain alongside the full and differential backups that are retained
For example, to create a full backup and retain the previous 7 full backups, you would execute the following command:
pgo backup hacluster --backup-opts="--type=full --repo1-retention-full=7"Scheduling Backups
Any effective disaster recovery strategy includes having regularly scheduled backups. The PostgreSQL Operator enables this through its scheduling sidecar that is deployed alongside the Operator.
Creating a Scheduled Backup
For example, to schedule a full backup once a day at midnight, you can execute the following command:
pgo create schedule hacluster --schedule="0 1 * * *" \
--schedule-type=pgbackrest --pgbackrest-backup-type=fullTo schedule an incremental backup once every 3 hours, you can execute the following command:
pgo create schedule hacluster --schedule="0 */3 * * *" \
--schedule-type=pgbackrest --pgbackrest-backup-type=incrYou can also create regularly scheduled backups and combine it with a retention policy. For example, using the above example of taking a nightly full backup, you can specify a policy of retaining 21 backups by executing the following command:
pgo create schedule hacluster --schedule="0 0 * * *" \
--schedule-type=pgbackrest --pgbackrest-backup-type=full \
--schedule-opts="--repo1-retention-full=21"Restore a Cluster
The PostgreSQL Operator supports the ability to perform a full restore on a
PostgreSQL cluster as well as a point-in-time-recovery using the pgo restore
command. Note that both of these options are destructive to the existing
PostgreSQL cluster; to “restore” the PostgreSQL cluster to a new deployment,
please see the clone section.
After a restore, there are some cleanup steps you will need to perform. Please review the Post Restore Cleanup section.
Full Restore
To perform a full restore of a PostgreSQL cluster, you can execute the following command:
pgo restore haclusterIf you want your PostgreSQL cluster to be restored to a specific node, you can execute the following command:
pgo restore hacluster --node-label=failure-domain.beta.kubernetes.io/zone=us-central1-aThere are very few reasons why you will want to execute a full restore. If you
want to make a copy of your PostgreSQL cluster, please use
pgo clone.
Point-in-time-Recovery (PITR)
The more likely scenario when performing a PostgreSQL cluster restore is to recover to a particular point-in-time (e.g. before a key table was dropped). For example, to restore a cluster to December 23, 2019 at 8:00am:
pgo restore hacluster --pitr-target="2019-12-23 08:00:00.000000+00" \
--backup-opts="--type=time"When the restore is complete, the cluster is immediately available for reads and
writes. To inspect the data before allowing connections, add pgBackRest’s
--target-action=pause option to the --backup-opts parameter.
The PostgreSQL Operator supports the full set of pgBackRest restore options,
which can be passed into the --backup-opts parameter. For more information,
please review the pgBackRest restore options
Post Restore Cleanup
After a restore is complete, you will need to re-enable high-availability on a PostgreSQL cluster manually. You can re-enable high-availability by executing the following command:
pgo update cluster hacluster --autofail=trueLogical Backups (pg_dump / pg_dumpall)
The PostgreSQL Operator supports taking logical backups with pg_dump and
pg_dumpall. While they do not provide the same performance and storage
optimizations as the physical backups provided by pgBackRest, logical backups
are helpful when one wants to upgrade between major PostgreSQL versions, or
provide only a subset of a database, such as a table.
Create a Logical Backup
To create a logical backup of a full database, you can run the following command:
pgo backup hacluster --backup-type=pgdumpYou can pass in specific options to --backup-opts, which can accept most of
the options that the pg_dump
command accepts. For example, to only dump the data from a specific table called
users:
pgo backup hacluster --backup-type=pgdump --backup-opts="-t users"To use pg_dumpall to create a logical backup of all the data in a PostgreSQL
cluster, you must pass the --dump-all flag in --backup-opts, i.e.:
pgo backup hacluster --backup-type=pgdump --backup-opts="--dump-all"Viewing Logical Backups
To view an available list of logical backups, you can use the pgo show backup
command:
pgo show backup --backup-type=pgdumpThis provides information about the PVC that the logical backups are stored on as well as the timestamps required to perform a restore from a logical backup.
Restore from a Logical Backup
To restore from a logical backup, you need to reference the PVC that the logical backup is stored to, as well as the timestamp that was created by the logical backup.
You can restore a logical backup using the following command:
pgo restore hacluster --backup-type=pgdump --backup-pvc=hacluster-pgdump-pvc \
--pitr-target="2019-01-15-00-03-25" -n pgouser1High-Availability: Scaling Up & Down
The PostgreSQL Operator supports a robust high-availability set up to ensure that your PostgreSQL clusters can stay up and running. For detailed information on how it works, please see the high-availability architecture section.
Creating a New Replica
To create a new replica, also known as “scaling up”, you can execute the following command:
pgo scale hacluster --replica-count=1If you wanted to add two new replicas at the same time, you could execute the following command:
pgo scale hacluster --replica-count=2Viewing Available Replicas
You can view the available replicas in a few ways. First, you can use pgo show cluster
to see the overall information about the PostgreSQL cluster:
pgo show cluster haclusterYou can also find specific replica names by using the --query flag on the
pgo failover and pgo scaledown commands, e.g.:
pgo failover --query haclusterManual Failover
The PostgreSQL Operator is set up with an automated failover system based on distributed consensus, but there may be times where you wish to have your cluster manually failover. If you wish to have your cluster manually failover, first, query your cluster to determine which failover targets are available. The query command also provides information that may help your decision, such as replication lag:
pgo failover --query haclusterOnce you have selected the replica that is best for your to failover to, you can perform a failover with the following command:
pgo failover hacluster --target=hacluster-abcdwhere hacluster-abcd is the name of the PostgreSQL instance that you want to
promote to become the new primary
Destroying a Replica
To destroy a replica, first query the available replicas by using the --query
flag on the pgo scaledown command, i.e.:
pgo scaledown hacluster --queryOnce you have picked the replica you want to remove, you can remove it by executing the following command:
pgo scaledown hacluster --target=hacluster-abcdwhere hacluster-abcd is the name of the PostgreSQL replica that you want to
destroy.
Cluster Maintenance & Resource Management
There are several operations that you can perform to modify a PostgreSQL cluster over its lifetime.
Modify CPU / Memory for a PostgreSQL Cluster
As database workloads change, it may be necessary to modify the CPU and memory
allocation for your PostgreSQL cluster. The PostgreSQL Operator allows for this
via the --cpu and --memory flags on the pgo update cluster
command. Similar to the create command, both flags accept values that follow the
Kubernetes quantity format.
For example, to update a PostgreSQL cluster to use 8 CPU cores and has 32 gibibytes of memory, you can use the following command:
pgo update cluster hacluster --cpu=8 --memory=32GiThe resource allocations apply to all instances in a PostgreSQL cluster: this means your primary and any replicas will have the same cluster resource allocations. Be sure to specify resource requests that your Kubernetes environment can support.
NOTE: This operation can cause downtime. Modifying the resource requests allocated to a Deployment requires that the Pods in a Deployment must be restarted. Each PostgreSQL instance is safely shutdown using the “fast” shutdown method to help ensure it will not enter crash recovery mode when a new Pod is created.
When the operation completes, each PostgreSQL instance will have the new resource allocations.
Adding a Tablespace to a Cluster
Based on your workload or volume of data, you may wish to add a tablespace to your PostgreSQL cluster.
You can add a tablespace to an existing PostgreSQL cluster with the
pgo update cluster command.
Adding a tablespace to a cluster uses a similar syntax to
creating a cluster with a tablespace, for example:
pgo update cluster hacluster \
--tablespace=name=tablespace3:storageconfig=storageconfignameNOTE: This operation can cause downtime. In order to add a tablespace to a PostgreSQL cluster, persistent volume claims (PVCs) need to be created and mounted to each PostgreSQL instance in the cluster. The act of mounting a new PVC to a Kubernetes Deployment causes the Pods in the deployment to restart.
Each PostgreSQL instance is safely shutdown using the “fast” shutdown method to help ensure it will not enter crash recovery mode when a new Pod is created.
When the operation completes, the tablespace will be set up and accessible to use within the PostgreSQL cluster.
For more information on tablespaces, please visit the tablespace section of the documentation.
Clone a PostgreSQL Cluster
You can create a copy of an existing PostgreSQL cluster in a new PostgreSQL
cluster by using the pgo clone command.
The command copies the pgBackRest repository from the existing cluster and
creates a new, single instance primary as its own cluster. To
create the new, single instance, copy of a PostgreSQL cluster, you can execute
the following command:
pgo clone hacluster newhaclusterClone a PostgreSQL Cluster to Different PVC Size
You can have a cloned PostgreSQL cluster use a different PVC size, which is useful when moving your PostgreSQL cluster to a larger PVC. For example, to clone a PostgreSQL cluster to a 256GiB PVC, you can execute the following command:
pgo clone hacluster newhacluster --pvc-size=256GiYou can also have the cloned PostgreSQL cluster use a larger pgBackRest backup repository by setting its PVC size. For example, to have a cloned PostgreSQL cluster use a 1TiB pgBackRest repository, you can execute the following command:
pgo clone hacluster newhacluster --pgbackrest-pvc-size=1TiEnable TLS
TLS allows secure TCP connections to PostgreSQL, and the PostgreSQL Operator makes it easy to enable this PostgreSQL feature. The TLS support in the PostgreSQL Operator does not make an opinion about your PKI, but rather loads in your TLS key pair that you wish to use for the PostgreSQL server as well as its corresponding certificate authority (CA) certificate. Both of these Secrets are required to enable TLS support for your PostgreSQL cluster when using the PostgreSQL Operator, but it in turn allows seamless TLS support.
Setup
There are three items that are required to enable TLS in your PostgreSQL clusters:
- A CA certificate
- A TLS private key
- A TLS certificate
There are a variety of methods available to generate these items: in fact, Kubernetes comes with its own certificate management system! It is up to you to decide how you want to manage this for your cluster. The PostgreSQL documentation also provides an example for how to generate a TLS certificate as well.
To set up TLS for your PostgreSQL cluster, you have to create two Secrets: one that contains the CA certificate, and the other that contains the server TLS key pair.
First, create the Secret that contains your CA certificate. Create the Secret as a generic Secret, and note that the following requirements must be met:
- The Secret must be created in the same Namespace as where you are deploying your PostgreSQL cluster
- The
nameof the key that is holding the CA must beca.crt
There are optional settings for setting up the CA secret:
- You can pass in a certificate revocation list (CRL) for the CA secret by
passing in the CRL using the
ca.crlkey name in the Secret.
For example, to create a CA Secret with the trusted CA to use for the PostgreSQL clusters, you could execute the following command:
kubectl create secret generic postgresql-ca --from-file=ca.crt=/path/to/ca.crtTo create a CA Secret that includes a CRL, you could execute the following command:
kubectl create secret generic postgresql-ca \
--from-file=ca.crt=/path/to/ca.crt \
--from-file=ca.crl=/path/to/ca.crlNote that you can reuse this CA Secret for other PostgreSQL clusters deployed by the PostgreSQL Operator.
Next, create the Secret that contains your TLS key pair. Create the Secret as a a TLS Secret, and note the following requirement must be met:
- The Secret must be created in the same Namespace as where you are deploying your PostgreSQL cluster
kubectl create secret tls hacluster-tls-keypair \
--cert=/path/to/server.crt \
--key=/path/to/server.keyNow you can create a TLS-enabled PostgreSQL cluster!
Create a TLS Enabled PostgreSQL Cluster
Using the above example, to create a TLS-enabled PostgreSQL cluster that can accept both TLS and non-TLS connections, execute the following command:
pgo create cluster hacluster-tls \
--server-ca-secret=hacluster-tls-keypair \
--server-tls-secret=postgresql-caIncluding the --server-ca-secret and --server-tls-secret flags automatically
enable TLS connections in the PostgreSQL cluster that is deployed. These flags
should reference the CA Secret and the TLS key pair Secret, respectively.
If deployed successfully, when you connect to the PostgreSQL cluster, assuming
your PGSSLMODE is set to prefer or higher, you will see something like this
in your psql terminal:
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Force TLS in a PostgreSQL Cluster
There are many environments where you want to force all remote connections to
occur over TLS, for example, if you deploy your PostgreSQL cluster’s in a public
cloud or on an untrusted network. The PostgreSQL Operator lets you force all
remote connections to occur over TLS by using the --tls-only flag.
For example, using the setup above, you can force TLS in a PostgreSQL cluster by executing the following command:
pgo create cluster hacluster-tls-only \
--tls-only \
--server-ca-secret=hacluster-tls-keypair --server-tls-secret=postgresql-caIf deployed successfully, when you connect to the PostgreSQL cluster, assuming
your PGSSLMODE is set to prefer or higher, you will see something like this
in your psql terminal:
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
If you try to connect to a PostgreSQL cluster that is deployed using the
--tls-only with TLS disabled (i.e. PGSSLMODE=disable), you will receive an
error that connections without TLS are unsupported.
Custom PostgreSQL Configuration
Customizing PostgreSQL configuration is currently not subject to the pgo
client, but given it is a common question, we thought it may be helpful to link
to how to do it from here. To find out more about how to
customize your PostgreSQL configuration,
please refer to the Custom PostgreSQL Configuration
section of the documentation.
pgAdmin 4: PostgreSQL Administration
pgAdmin 4 is a popular graphical user interface that lets you work with PostgreSQL databases from both a desktop or web-based client. In the case of the PostgreSQL Operator, the pgAdmin 4 web client can be deployed and synchronized with PostgreSQL clusters so that users can administrate their databases with their PostgreSQL username and password.
For example, let’s work with a PostgreSQL cluster called hippo that has a user named hippo with password datalake, e.g.:
pgo create cluster hippo --username=hippo --password=datalake
Once the hippo PostgreSQL cluster is ready, create the pgAdmin 4 deployment
with the pgo create pgadmin
command:
pgo create pgadmin hippo
This creates a pgAdmin 4 deployment unique to this PostgreSQL cluster and
synchronizes the PostgreSQL user information into it. To access pgAdmin 4, you
can set up a port-forward to the Service, which follows the
pattern <clusterName>-pgadmin, to port 5050:
kubectl port-forward svc/hippo-pgadmin 5050:5050
Point your browser at http://localhost:5050 and use your database username
(e.g. hippo) and password (e.g. datalake) to log in.
(Note: if your password does not appear to work, you can retry setting up the
user with the pgo update user
command: pgo update user hippo --password=datalake)
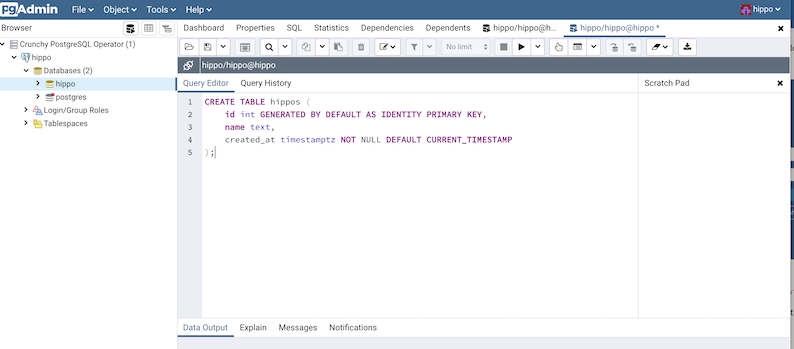
The pgo create user, pgo update user, and pgo delete user commands are
synchronized with the pgAdmin 4 deployment. Any user with credentials to this
PostgreSQL cluster will be able to log in and use pgAdmin 4:
You can remove the pgAdmin 4 deployment with the pgo delete pgadmin
command.
For more information, please read the pgAdmin 4 Architecture section of the documentation.
Standby Clusters: Multi-Cluster Kubernetes Deployments
A standby PostgreSQL cluster can be used to create an advanced high-availability set with a PostgreSQL cluster running in a different Kubernetes cluster, or used for other operations such as migrating from one PostgreSQL cluster to another. Note: this is not high availability per se: a high-availability PostgreSQL cluster will automatically fail over upon a downtime event, whereas a standby PostgreSQL cluster must be explicitly promoted.
With that said, you can run multiple PostgreSQL Operators in different Kubernetes clusters, and the below functionality will work!
Below are some commands for setting up and using standby PostgreSQL clusters. For more details on how standby clusters work, please review the section on Kubernetes Multi-Cluster Deployments.
Creating a Standby Cluster
Before creating a standby cluster, you will need to ensure that your primary cluster is created properly. Standby clusters require the use of S3 or equivalent S3-compatible storage system that is accessible to both the primary and standby clusters. For example, to create a primary cluster to these specifications:
pgo create cluster hippo --pgbouncer --replica-count=2 \
--pgbackrest-storage-type=local,s3 \
--pgbackrest-s3-key=<redacted> \
--pgbackrest-s3-key-secret=<redacted> \
--pgbackrest-s3-bucket=watering-hole \
--pgbackrest-s3-endpoint=s3.amazonaws.com \
--pgbackrest-s3-region=us-east-1 \
--password-superuser=supersecrethippo \
--password-replication=somewhatsecrethippo \
--password=opensourcehippoBefore setting up the standby PostgreSQL cluster, you will need to wait a few moments for the primary PostgreSQL cluster to be ready. Once your primary PostgreSQL cluster is available, you can create a standby cluster by using the following command:
pgo create cluster hippo-standby --standby --replica-count=2 \
--pgbackrest-storage-type=s3 \
--pgbackrest-s3-key=<redacted> \
--pgbackrest-s3-key-secret=<redacted> \
--pgbackrest-s3-bucket=watering-hole \
--pgbackrest-s3-endpoint=s3.amazonaws.com \
--pgbackrest-s3-region=us-east-1 \
--pgbackrest-repo-path=/backrestrepo/hippo-backrest-shared-repo \
--password-superuser=supersecrethippo \
--password-replication=somewhatsecrethippo \
--password=opensourcehippoThe standby cluster will take a few moments to bootstrap, but it is now set up!
Promoting a Standby Cluster
Before promoting a standby cluster, it is first necessary to shut down the primary cluster, otherwise you can run into a potential “split-brain“ scenario (if your primary Kubernetes cluster is down, it may not be possible to do this).
To shutdown, run the following command:
pgo update cluster hippo --shutdown
Once it is shut down, you can promote the standby cluster:
pgo update cluster hippo-standby --promote-standby
The standby is now an active PostgreSQL cluster and can start to accept writes.
To convert the previous active cluster into a standby cluster, you can run the following command:
pgo update cluster hippo --enable-standby
This will take a few moments to make this PostgreSQL cluster into a standby cluster. When it is ready, you can start it up with the following command:
pgo update cluster hippo --startup
Monitoring
View Disk Utilization
You can see a comparison of Postgres data size versus the Persistent volume claim size by entering the following:
pgo df hacluster -n pgouser1PostgreSQL Metrics via pgMonitor
You can view metrics about your PostgreSQL cluster using the pgMonitor stack by deploying the “crunchy-collect” sidecar with the PostgreSQL cluster:
pgo create cluster hacluster --metrics
Note: To store and visualize the metrics, you must deploy Prometheus and Grafana with yoru PostgreSQL cluster. For instructions on installing Grafana and Prometheus in your environment, please review the installation instructions for the metrics stack.
Labels
Labels are a helpful way to organize PostgreSQL clusters, such as by application type or environment. The PostgreSQL Operator supports managing Kubernetes Labels as a convenient way to group PostgreSQL clusters together.
You can view which labels are assigned to a PostgreSQL cluster using the
pgo show cluster command. You are also
able to see these labels when using kubectl or oc.
Add a Label to a PostgreSQL Cluster
Labels can be added to PostgreSQL clusters using the pgo label
command. For example, to add a label with a key/value pair of env=production,
you could execute the following command:
pgo label hacluster --label=env=productionAdd a Label to Multiple PostgreSQL Clusters
You can add also add a label to multiple PostgreSQL clusters simultaneously
using the --selector flag on the pgo label command. For example, to add a
label with a key/value pair of env=production to clusters that have a label
key/value pair of app=payment, you could execute the following command:
pgo label --selector=app=payment --label=env=productionPolicy Management
Create a Policy
To create a SQL policy, enter the following:
pgo create policy mypolicy --in-file=mypolicy.sql -n pgouser1
This examples creates a policy named mypolicy using the contents of the file mypolicy.sql which is assumed to be in the current directory.
You can view policies as following:
pgo show policy --all -n pgouser1
Apply a Policy
pgo apply mypolicy --selector=environment=prod
pgo apply mypolicy --selector=name=hacluster
Advanced Operations
Connection Pooling via pgBouncer
To add a pgbouncer Deployment to your Postgres cluster, enter:
pgo create cluster hacluster --pgbouncer -n pgouser1
You can add pgbouncer after a Postgres cluster is created as follows:
pgo create pgbouncer hacluster
pgo create pgbouncer --selector=name=hacluster
You can also specify a pgbouncer password as follows:
pgo create cluster hacluster --pgbouncer --pgbouncer-pass=somepass -n pgouser1
You can remove a pgbouncer from a cluster as follows:
pgo delete pgbouncer hacluster -n pgouser1
Query Analysis via pgBadger
You can create a pgbadger sidecar container in your Postgres cluster pod as follows:
pgo create cluster hacluster --pgbadger -n pgouser1
Create a Cluster using Specific Storage
pgo create cluster hacluster --storage-config=somestorageconfig -n pgouser1
Likewise, you can specify a storage configuration when creating a replica:
pgo scale hacluster --storage-config=someslowerstorage -n pgouser1
This example specifies the somestorageconfig storage configuration to be used by the Postgres cluster. This lets you specify a storage configuration that is defined in the pgo.yaml file specifically for a given Postgres cluster.
You can create a Cluster using a Preferred Node as follows:
pgo create cluster hacluster --node-label=speed=superfast -n pgouser1
That command will cause a node affinity rule to be added to the Postgres pod which will influence the node upon which Kubernetes will schedule the Pod.
Likewise, you can create a Replica using a Preferred Node as follows:
pgo scale hacluster --node-label=speed=slowerthannormal -n pgouser1
Create a Cluster with LoadBalancer ServiceType
pgo create cluster hacluster --service-type=LoadBalancer -n pgouser1
This command will cause the Postgres Service to be of a specific type instead of the default ClusterIP service type.
Namespace Operations
Create an Operator namespace where Postgres clusters can be created and managed by the Operator:
pgo create namespace mynamespace
Update a Namespace to be able to be used by the Operator:
pgo update namespace somenamespace
Delete a Namespace:
pgo delete namespace mynamespace
PostgreSQL Operator User Operations
PGO users are users defined for authenticating to the PGO REST API. You can manage those users with the following commands:
pgo create pgouser someuser --pgouser-namespaces="pgouser1,pgouser2" --pgouser-password="somepassword" --pgouser-roles="pgoadmin"
pgo create pgouser otheruser --all-namespaces --pgouser-password="somepassword" --pgouser-roles="pgoadmin"
Update a user:
pgo update pgouser someuser --pgouser-namespaces="pgouser1,pgouser2" --pgouser-password="somepassword" --pgouser-roles="pgoadmin"
pgo update pgouser otheruser --all-namespaces --pgouser-password="somepassword" --pgouser-roles="pgoadmin"
Delete a PGO user:
pgo delete pgouser someuser
PGO roles are also managed as follows:
pgo create pgorole somerole --permissions="Cat,Ls"
Delete a PGO role with:
pgo delete pgorole somerole
Update a PGO role with:
pgo update pgorole somerole --permissions="Cat,Ls"
PostgreSQL Cluster User Operations
Managed Postgres users can be viewed using the following command:
pgo show user hacluster
Postgres users can be created using the following command examples:
pgo create user hacluster --username=somepguser --password=somepassword --managed
pgo create user --selector=name=hacluster --username=somepguser --password=somepassword --managed
Those commands are identical in function, and create on the hacluster Postgres cluster, a user named somepguser, with a password of somepassword, the account is managed meaning that these credentials are stored as a Secret on the Kubernetes cluster in the Operator namespace.
Postgres users can be deleted using the following command:
pgo delete user hacluster --username=somepguser
That command deletes the user on the hacluster Postgres cluster.
Postgres users can be updated using the following command:
pgo update user hacluster --username=somepguser --password=frodo
That command changes the password for the user on the hacluster Postgres cluster.