Provisioning
What happens when the Crunchy PostgreSQL Operator creates a PostgreSQL cluster?
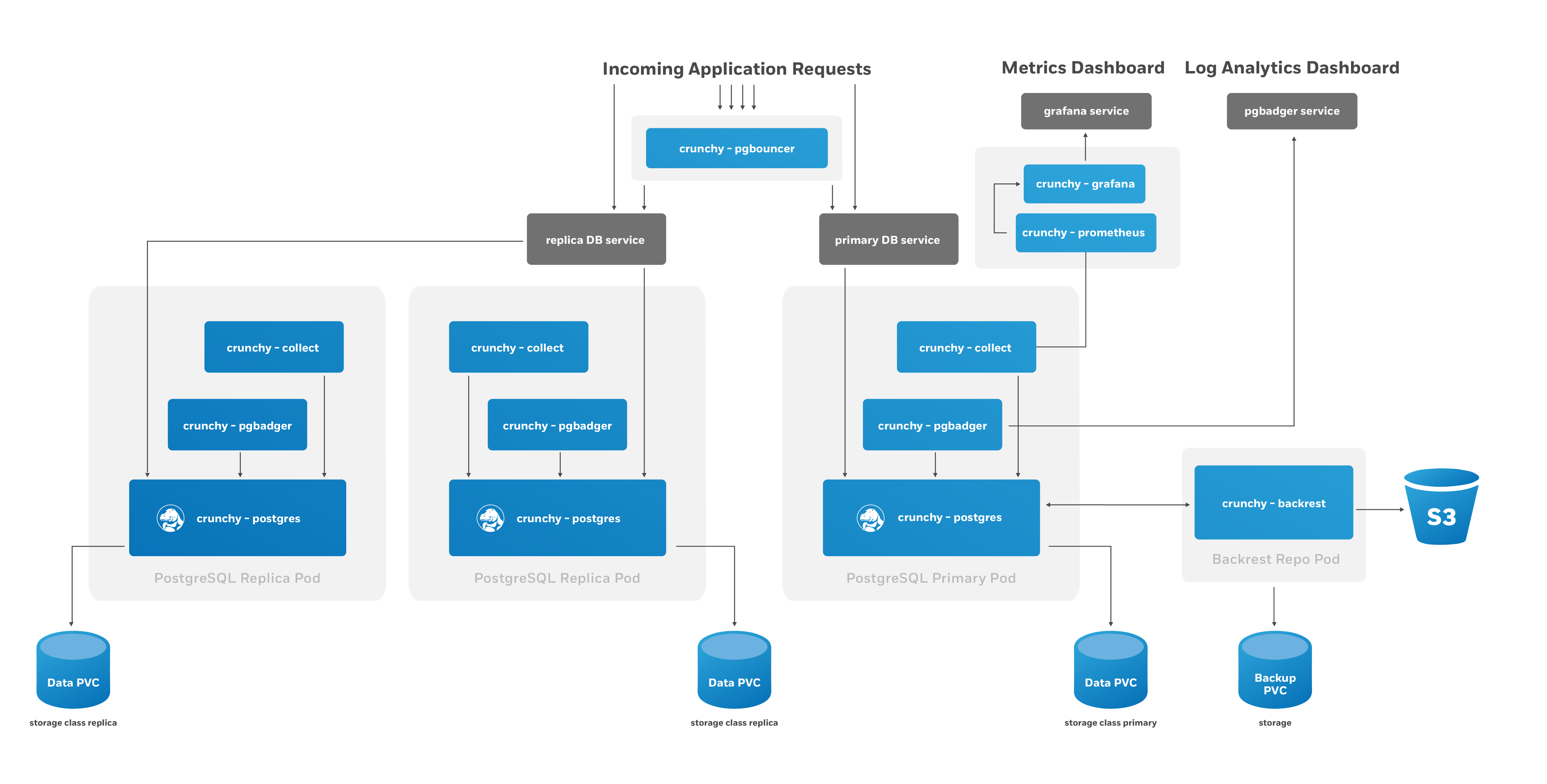
First, an entry needs to be added to the Pgcluster CRD that provides the
essential attributes for maintaining the definition of a PostgreSQL cluster.
These attributes include:
- Cluster name
- The storage and resource definitions to use
- References to any secrets required, e.g. ones to the pgBackRest repository
- High-availability rules
- Which sidecars and ancillary services are enabled, e.g. pgBouncer, pgMonitor
After the Pgcluster CRD entry is set up, the PostgreSQL Operator handles various tasks to ensure that a healthy PostgreSQL cluster can be deployed. These include:
- Allocating the PersistentVolumeClaims that are used to store the PostgreSQL data as well as the pgBackRest repository
- Setting up the Secrets specific to this PostgreSQL cluster
- Setting up the ConfigMap entries specific for this PostgreSQL cluster, including entries that may contain custom configurations as well as ones that are used for the PostgreSQL cluster to manage its high-availability
- Creating Deployments for the PostgreSQL primary instance and the pgBackRest repository
You will notice the presence of a pgBackRest repository. As of version 4.2, this is a mandatory feature for clusters that are deployed by the PostgreSQL Operator. In addition to providing an archive for the PostgreSQL write-ahead logs (WAL), the pgBackRest repository serves several critical functions, including:
- Used to efficiently provision new replicas that are added to the PostgreSQL cluster
- Prevent replicas from falling out of sync from the PostgreSQL primary by allowing them to replay old WAL logs
- Allow failed primaries to automatically and efficiently heal using the “delta restore” feature
- Serves as the basis for the cluster cloning feature
- …and of course, allow for one to take full, differential, and incremental backups and perform full and point-in-time restores
The pgBackRest repository can be configured to use storage that resides within
the Kubernetes cluster (the local option), Amazon S3 or a storage system that
uses the S3 protocol (the s3 option), or both (local,s3).
Once the PostgreSQL primary instance is ready, there are two follow up actions that the PostgreSQL Operator takes to properly leverage the pgBackRest repository:
- A new pgBackRest stanza is created
- An initial backup is taken to facilitate the creation of any new replica
At this point, if new replicas were requested as part of the pgo create
command, they are provisioned from the pgBackRest repository.
There is a Kubernetes Service created for the Deployment of the primary PostgreSQL instance, one for the pgBackRest repository, and one that encompasses all of the replicas. Additionally, if the connection pooler pgBouncer is deployed with this cluster, it will also have a service as well.
An optional monitoring sidecar can be deployed as well. The sidecar, called
collect, uses the crunchy-collect container that is a part of pgMonitor and
scrapes key health metrics into a Prometheus instance. See Monitoring for more
information on how this works.
Horizontal Scaling
There are many reasons why you may want to horizontally scale your PostgreSQL cluster:
- Add more redundancy by having additional replicas
- Leveraging load balancing for your read only queries
- Add in a new replica that has more storage or a different container resource profile, and then failover to that as the new primary
and more.
The PostgreSQL Operator enables the ability to scale up and down via the
pgo scale and pgo scaledown commands respectively. When you run pgo scale,
the PostgreSQL Operator takes the following steps:
- The PostgreSQL Operator creates a new Kubernetes Deployment with the
information specified from the
pgo scalecommand combined with the information already stored as part of the managing the existing PostgreSQL cluster - During the provisioning of the replica, a pgBackRest restore takes place in order to bring it up to the point of the last backup. If data already exists as part of this replica, then a “delta restore” is performed. (NOTE: If you have not taken a backup in awhile and your database is large, consider taking a backup before performing scaling up.)
- The new replica boots up in recovery mode and recovers to the latest point in time. This allows it to catch up to the current primary.
- Once the replica has recovered, it joins the primary as a streaming replica!
If pgMonitor is enabled, a collect sidecar is also added to the replica
Deployment.
Scaling down works in the opposite way:
- The PostgreSQL instance on the scaled down replica is stopped. By default, the
data is explicitly wiped out unless the
--keep-dataflag onpgo scaledownis specified. Once the data is removed, the PersistentVolumeClaim (PVC) is also deleted - The Kubernetes Deployment associated with the replica is removed, as well as any other Kubernetes objects that are specifically associated with this replcia
Custom Configuration
PostgreSQL workloads often need tuning and additional configuration in production environments, and the PostgreSQL Operator allows for this via its ability to manage custom PostgreSQL configuration.
The custom configuration can be edit from a ConfigMap
that follows the pattern of <clusterName>-pgha-config, where <clusterName>
would be hippo in pgo create cluster hippo. When the ConfigMap is edited,
the changes are automatically pushed out to all of the PostgreSQL instances
within a cluster.
For more information on how this works and what configuration settings are editable, please visit the “Custom PostgreSQL configuration“ section of the documentation.
Deprovisioning
There may become a point where you need to completely deprovision, or delete, a
PostgreSQL cluster. You can delete a cluster managed by the PostgreSQL Operator
using the pgo delete command. By default, all data and backups are removed
when you delete a PostgreSQL cluster, but there are some options that allow you
to retain data, including:
--keep-backups- this retains the pgBackRest repository. This can be used to restore the data to a new PostgreSQL cluster.--keep-data- this retains the PostgreSQL data directory (akaPGDATA) from the primary PostgreSQL instance in the cluster. This can be used to recreate the PostgreSQL cluster of the same name.
When the PostgreSQL cluster is deleted, the following takes place:
- All PostgreSQL instances are stopped. By default, the data is explicitly wiped
out unless the
--keep-dataflag onpgo scaledownis specified. Once the data is removed, the PersistentVolumeClaim (PVC) is also deleted - Any Services, ConfigMaps, Secrets, etc. Kubernetes objects are all deleted
- The Kubernetes Deployments associated with the PostgreSQL instances are removed, as well as the Kubernetes Deployments associated with pgBackRest repository and, if deployed, the pgBouncer connection pooler